1 引言
PageRank 算法被广泛用于确定网页的重要性, 是 Web 搜索中最重要的问题之一, 最早由谷歌的创始人 Larry Page 和 Sergey Brin 在一系列论文[1 4] 中提出. 该模型的核心思想是通过网页之间的链接关系来评估网页的重要性. 随着时间的推移, PageRank 模型已经被广泛应用于各种科学问题的分析, 包括计算化学[5 ] ,生物信息学[6 ] , 软件调试[7 ] 等领域.
PageRank 问题的数学表述可以归结为计算 Google 矩阵的主特征向量. Google 矩阵是一个维度超过数十亿的大型稀疏马尔可夫矩阵, 其主特征向量被称为 PageRank 向量. PageRank 问题可以用以下方程表示
(1.1) $\begin{equation}\label{1.1}G x=x, ||x||_{1}=1, \quad x>0,\end{equation}$
其中, Google 矩阵 $G=\alpha P+(1-\alpha) ve^{\top}$ $\alpha\in (0,1)$ $P\in\mathbb{R}^{n\times n}$ $1$ $e$ $1$ $v=\frac{e}{n}$
PageRank 问题 (1.1) 可以重构为以下线性系统
(1.2) $\begin{equation}\label{1.2}(I- \alpha P)x=(1- \alpha)v,\end{equation}$
其中 $I\in\mathbb{R}^{n\times n}$
在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量.
然而, 当 Krylov 子空间的维数增大时, 基于 Arnoldi 的求解器在内存和计算成本方面会显著增加. 相反, 如果维数过低, 这些方法有时可能无法有效加速基本的幂法, 特别是在阻尼系数较高时, 甚至可能出现停滞不前的情况. 为攻克这一难题, Hessenberg 于 1940 年引入海森伯格约简过程[13 ] , 并由于其较低的算术和存储需求, 该过程最近被重新启用, 以建立许多针对稀疏矩阵系统的具有成本效益的 Krylov 子空间求解器. 在此基础之上, 顾等人在 2019 年将 Hessenberg 过程与重新启动的技术相结合, 提出了 Hessenberg-type算法[14 ] 以用于计算 PageRank 向量. 胡等人在 2024 年将外推过程引入到 Hessenberg 型算法中, 得到了新的 Hessenberg-extrapolation[15 ] 算法. 本文尝试使用 Chebyshev 多项式来加速 Hessenberg 算法, 从而提出了一种新的 Hessenberg-Chebyshev 算法并详细探讨了该算法的构造和收敛性. 数值结果表明, 当阻尼因子 $\alpha$
本文的其余部分组织如下. 在第 2 节中, 我们介绍了用于计算 PageRank 的 Hessenberg-type 算法; 在第 3 节中, 我们提出了计算 PageRank 的 Hessenberg-Chebyshev 算法, 在第 4 节中对该算法的收敛性进行分析; 数值实验和对比结果在第 5 节; 最后, 在第 6 节给出结论.
2 计算 PageRank 的 Hessenberg-type 算法
在本节中, 将对用于计算 PageRank 的 Hessenberg-type 算法[14 ] 进行介绍. Hessenberg-type 算法和 Arnoldi-type算法是相似的, Hessenberg-type 算法也产生 Krylov 子空间的一组基, 但这组基不是正交的. 下面给出了计算 PageRank 的 Hessenberg-type 算法.
注2.1 算法 1 的第 22 行的 $\sigma _{m}$ $H_{m+1,m}-[I_{m};0]$ $20$ $v_{m}$ $L_{m}$ $7$ $19$ $l_{j}$ $22$ $u_{m}$
Hessenberg 过程是一种斜投影技术, 它将给定的非对称矩阵 $A\in\mathbb{R}^{n\times n}$ $H_{m}$ $A$ $A-\lambda_{i}I$ $\{\lambda_{i}\}_{i=1}^m $ $L_m$
表1 中显示了执行 Hessenberg-type 算法和 Arnoldi-type 算法一个周期所需的计算工作量. 这里 $N_z$ $A$
3 求解 PageRank 的 Hessenberg-Chebyshev 算法
在本节中, 我们尝试用 Chebyshev 加速 Hessenberg-type 算法用于计算 PageRank, 从而开发了 Hessenberg-Chebyshev 新算法. 我们使用 Chebyshev 多项式[16 ] 来改进 Hessenberg-type 算法以计算 PageRank. 假设 Google 矩阵 $A$ $1 = |\lambda_1| > |\lambda_2| \geq \cdots \geq |\lambda_n|$ . 令 $P_{l}$ $l$ $(\lambda_{i},\mu_i), i = 1, 2, \cdots, n$ $A$
其中 $z_0$ $p_l$ $l$ $p_l$ $z_l$ $\lambda_1 = 1$ $A$ $\mu_1$ . 在特征分解下 $z_0 = \sum_{i=1}^{n} y_i\mu_i$ $\|\mu_i\|_2 = 1$ $y_i \neq 0, i = 1, 2, \cdots, n$ $z_l$
(3.1) $\begin{equation} z_l = p_{l}(A) z_{0}=\sum_{i=1}^{n} y_{i} p_{l}\left(\lambda_{i}\right) \mu_{i}=y_{1} p_{l}\left(\lambda_{1}\right) \mu_{1}+\sum_{i=2}^{n}y_{i} p_{l}\left(\lambda_{i}\right) \mu_{i}. \end{equation}$
因此, 我们希望多项式 $p_l$ $p_l(\lambda_i), i = 2, 3, \cdots, n$ $p_l(\lambda_1) = 1$ . 然而, 在没有获得 $A$ $A$ $\lambda_1$ $\Omega$
设 $\Omega(d, c, \alpha)$ $d$ $c$ $\alpha$
(3.2) $\begin{equation} p_{l}(\lambda)=\frac{T_{l}[(\lambda-d) / c]}{T_{l}\left[\left(\lambda_{1}-d\right) / c\right]}, \end{equation}$
(3.3) $\begin{equation} T_{l}(z)=\frac{1}{2}\left(\omega^{l}+\omega^{-l}\right), \quad z=\frac{1}{2}\left(\omega+\omega^{-1}\right), \end{equation}$
是第一类 $l$ 16 ].
实际上, 计算 $z_l = p_l(A)z_0$
(3.4) $\begin{equation} T_{0}(z)=1, \quad T_{1}(z)=z, \quad T_{l+1}(z)=2 z T_{l}(z)-T_{l-1}(z), \quad l=1,2, \cdots. \end{equation}$
设 $ \rho_{l}=T_{l}\left[\left(\lambda_{1}-d\right) / c\right](l=0,1, \cdots) $
(3.5) $\begin{equation} \rho_{l+1} p_{l+1}(\lambda)=T_{l+1}[(\lambda-d) / c]=2 \frac{\lambda-d}{c} \rho_{l} p_{l}(\lambda)-\rho_{l-1} p_{l-1}(\lambda), \end{equation}$
此外, 令 $ \sigma_{l+1}=\rho_{l} / \rho_{l+1} $
(3.6) $\begin{equation} p_{l+1}(\lambda) = 2\sigma_{l+1}p_l(\lambda) - \sigma_{l}\sigma_{l+1}p_{l-1}(\lambda), \end{equation}$
(3.7) $\begin{equation} \sigma_{1}=\frac{c}{\lambda_{1}-d}, \quad \sigma_{l+1}=\frac{1}{\frac{1}{\sigma_{l}}-\sigma_{l}}, \quad l=1,2, \cdots \end{equation}$
最后, 根据 (3.6) 和 (3.7) 式, 得到向量 $z_l= p_l(A)z_0$ . 现在我们应用 Chebyshev 多项式来加速 Hessenberg 算法以计算 PageRank, 具体的算法如下所示
现在我们关注算法 2 的计算成本并与 Hessenberg-type 算法进行比较. 在每次迭代中, 算法 2 基本运算是矩阵向量积, 在 $m$ $m$ $l$ $2n(m+l+3)N_z$ 表2 所示.
虽然算法 2 的每次迭代要进行的计算成本比 Hessenberg-type 算法高, 但是算法 2 所需迭代次数远小于 Hessenberg-type 算法, 这在第五部分数值实验中我们进行了验证.
4 收敛性分析
引理4.1 [17 ] 设 $P$ $n\times n$ $\alpha$ $0<\alpha<1$ $E$ $n\times n$ $E=ve^\top $ $e$ $1$ $n$ $v$ $1$ $n$ $A=\alpha P+(1-\alpha)E$ $A$ $\lambda_1=1$ $|\lambda_2|\le\alpha $ .
定理4.1 假设 $x^{(k)}$ $\mathrm{PageRank}$ $k$
(4.1) $\begin{equation} x^{(k)}=\theta_{1} \mu_{1}+\theta_{2} \mu_{2}+\cdots+\theta_{n} \mu_{\mathrm{n}}. \end{equation}$
其中 $\theta_{i}\ne0$ $i=1, 2, 3\cdots, n$ . 在迭代过程中进一步假设椭圆为 $E(d, c, a)$ $d$ $c$ $a$ $c$
(4.2) $\begin{equation} \left|\sin \angle\left(x^{(k+1)}, \mu_{1}\right)\right| \leq \max _{i \neq 1}\left(\frac{\left|\lambda_{i}-d_{*}\right|}{1-d_{*}}\right)^{l}\left(\sum_{i=2}^{n} \frac{\left|\theta_{i}\right|}{\left|\theta_{1}\right|}\right) \epsilon_{0}, \end{equation}$
其中 $d_{*}$ $\Phi(d) = \max _{i \neq 1}\left(\frac{\left|\lambda_{i}-d\right|}{1-d}\right)$ $[-\alpha, \alpha]$ $\epsilon_{0} = \min _{q \in P_{m-1}, \left(\lambda_{1}\right)=1} \max _{\lambda \in\Lambda / \lambda_{1}}|q(\lambda)|$ .
证 根据算法 2 的迭代过程, 我们首先通过 $m$ $x^{\left(k+\frac{1}{2}\right)}$ $\mathcal{K}_{m}\left(A, x^{(k)}\right)$ $x^{\left(k+\frac{1}{2}\right)}=q_{m-1}(A) x^{(k)}$ $q_{m-1}(\lambda)$ $m-1$ $\min _{\varphi \in P_{m-1}, q\left(\lambda_{1}\right)=1} \max _{\lambda \in \Lambda / \lambda_{1}}|q(\lambda)|$ .
另一方面, 通过 $x^{(k)}$ $x^{\left(k+\frac{1}{2}\right)}$
(4.3) $\begin{equation} x^{\left(k+\frac{1}{2}\right)}=\theta_{1} q_{m-1}\left(\lambda_{1}\right) \mu_{1}+\theta_{2} q_{m-1}\left(\lambda_{2}\right) \mu_{2}+\cdots+\theta_{n} q_{m-1}\left(\lambda_{n}\right) \mu_{n}, \end{equation}$
因此, 第 $(k+1)$ $x^{(k+1)}=p_{l}(A) x^{\left(k+\frac{1}{2}\right)}$ $p_{l}(\lambda)$
(4.4) $\begin{equation} x^{(k+1)}=\theta_{1} p_{l}\left(\lambda_{1}\right) q_{m-1}\left(\lambda_{1}\right) \mu_{1}+\theta_{2} p_{l}\left(\lambda_{2}\right) q_{m-1}\left(\lambda_{2}\right) \mu_{2}+\cdots+\theta_{n} p_{l}\left(\lambda_{n}\right) q_{m-1}\left(\lambda_{n}\right) \mu_{n}. \end{equation}$
(4.5) $\begin{equation} \begin{aligned} \mid \sin \angle(x^{(k+1)}, \mu_{1})| & \leq \frac{\left\|\theta_{2} p_{l}\left(\lambda_{2}\right) q_{m-1}\left(\lambda_{2}\right) \mu_{2}+\cdots+\theta_{n} p_{l}\left(\lambda_{n}\right) q_{m-1}\left(\lambda_{n}\right) \mu_{n}\right\|}{\left\|\theta_{1} p_{l}\left(\lambda_{1}\right) q_{m-1}\left(\lambda_{1}\right) \mu_{1}\right\|} \\ & \leq \frac{\left|\theta_{2}\right|\left|p _ { l } ( \lambda _ { 2 } ) \left\|\left|q_{m-1}\left(\lambda_{2}\right)\right|+\cdots+\left|\theta_{n}\right|\left|p_{l}\left(\lambda_{n}\right) \|\right| q_{m-1}\left(\lambda_{n}\right) \mid\right.\right.}{\left|\theta_{1} \| q_{m-1}\left(\lambda_{1}\right)\right|} \\ & \leq \max _{i \neq 1} \frac{\left|q_{m-1}\left(\lambda_{i}\right)\right|}{\left|q_{m-1}\left(\lambda_{1}\right)\right|} \max _{i \neq 1}\left|p_{l}\left(\lambda_{i}\right)\right|\left(\sum_{i=2}^{n} \frac{\left|\theta_{i}\right|}{\left|\theta_{1}\right|}\right) \\ & =\epsilon_{0}\left(\sum_{i=2}^{n} \frac{\left|\theta_{i}\right|}{\left|\theta_{1}\right|}\right) \max _{i \neq 1}\left|p_{l}\left(\lambda_{1}\right)\right|. \end{aligned} \end{equation}$
的值. 根据 (3.2) 式中 Chebyshev 多项式的定义, 可知道
(4.6) $\begin{equation} p_{\mathrm{l}}\left(\lambda_{i}\right)=\frac{\omega_{1}^{l}+\omega_{i}^{-l}}{\omega_{1}^{l}+\omega_{1}^{-l}}, \end{equation}$
已知 $\omega_{i}=\omega_{i}^{ \pm}=\frac{\lambda_{i}-d}{c} \pm \sqrt{\left(\frac{\lambda_{i}-d}{c}\right)^{2}-1}, i=2,3, \cdots, n$ $\omega_{1}=\omega_{1}^{ \pm}=\frac{1-d}{c} \pm \sqrt{\left(\frac{1-d}{c}\right)^{2}-1}$ . 在后续的讨论中, 取 $\omega_{i}=\omega_{i}^{+}, i=1,2, \cdots, n$ $\omega_{i}=\omega_{i}^{-}$ $\omega_{i}=\omega_{i}^{+}$ $p_{l}\left(\lambda_{i}\right)$ $\left|\omega_{i}\right| \geq 1$ $\left|\omega_{i}\right|^{-1}>1$ $\left|p_{\mathrm{l}}\left(\lambda_{i}\right)\right|$
(4.7) $\begin{equation} \left|p_{l}\left(\lambda_{i}\right)\right| \leq \frac{\left|\omega_{i}\right|^{l}+1}{\omega_{1}^{l}} \leq \frac{\left(\left|\lambda_{i}-d\right|+\sqrt{\left|\lambda_{i}-d\right|^{2}+c^{2}}\right)^{l}+c^{l}}{\left(1-d+\sqrt{(1-d)^{2}-c^{2}}\right)^{l}}:=\kappa(c). \end{equation}$
注意, $\kappa(c)$ $(0,1-d)$ $\lim _{c \rightarrow 0} \kappa(c) = \left(\frac{|\lambda_{i}-d|}{1-d}\right)^{l}$ .
5 数值实验
在本节中, 我们首先讨论重启数 $m$ $l$ 18 ]中的 Arnoldi-Chebyshev (AC) 算法. 针对表3 中的矩阵进行测试, 这些矩阵可以在 https://sparse.tamu.edu/ 上下载获得, 同时也列出了这些矩阵的一些性质, 其中 $n$ $nnz$ $\text{den}=\frac{nnz}{n\times n}\times 100\% $ .
为了公平起见, 本节中所有算法都以相同的初始向量 $v_{0}=e/n,e=[\cdots,1]^{\top}$ $\alpha=0.9,0.95,0.99,0.995$ . 在 Hessenberg-Chebyshev 算法中, 我们每个周期运行 Hessenberg 过程两次, 所有算法的容差为 $tol=10^{-8}$ . 在数值实验中, 为了简单起见我们将 $\mathrm{Hessenberg}$ - $\mathrm{Chebyshev}$ $c$ $0.01$ $d$ $0$ .
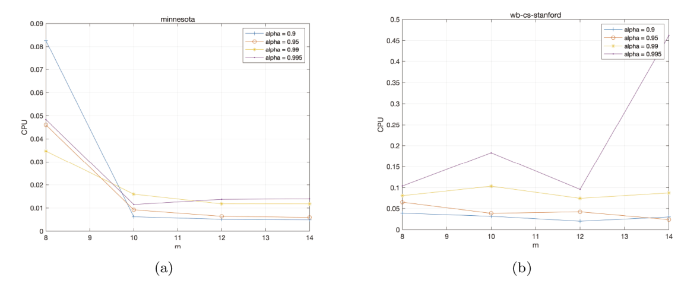
例 5.1 在本例中, 我们通过分析 $\mathrm{Minnesota}$ $\mathrm{wb}$ - $\mathrm{cs}$ - $\mathrm{stanford}$ $\mathrm{Hessenberg}$ - $\mathrm{Chebyshev}$ $m$ 图1 显示了当 $\alpha=0.9,0.95,0.99,0.995$ $m=8,10,12,14,16$ $\mathrm{Hessenberg}$ - $\mathrm{Chebyshev}$ $m$
图1
图1
Minnesota 和 wb-cs-stanford 矩阵关于 Hessenberg-Chebyshev 算法的迭代时间随重启次数 $m$
经过对实验数据的深入分析, 我们观察到重启次数 $m$ $\mathrm{Minnesota}$ $\alpha$ $m$ $m = 8$ $m = 10$ $m$ $\mathrm{wb}$ - $\mathrm{cs}$ - $\mathrm{stanford}$ $\alpha$ $0.995$ $m$ $m$ $\alpha$ $0.995$ $m$ $m$ $m$ $m$
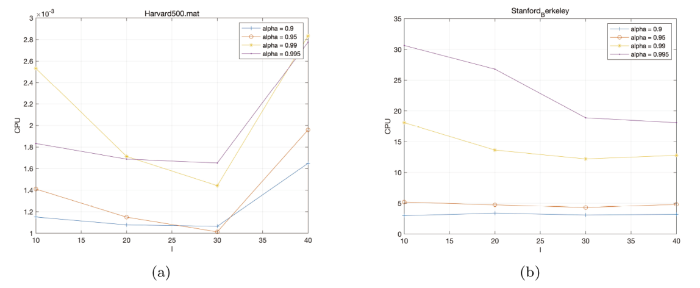
例 5.2 在本例中, 我们取 $m=10$ $\mathrm{Chebyshev}$ $l$ 图2 中绘制了阻尼因子 $\alpha=0.9, 0.95, 0.99, 0.995$ $\mathrm{Chebyshev}$ $l=10, 20, 30, 40$ $\mathrm{Harvard500}$ $\mathrm{Stanford}$ - $\mathrm{Berkeley }$ $\mathrm{Hessenberg}$ - $\mathrm{Chebyshev}$ $\mathrm{Chebyshev}$ $l$
图2
图2
Harvard500 和 Stanford-Berkeley 矩阵关于 Hessenberg-Chebyshev 算法的迭代时间随步长 $l$
从上图的数据分析中, 我们可以清晰地观察到, $\mathrm{Chebyshev}$ $l$ $\alpha$ $\mathrm{Chebyshev}$ $\mathrm{Chebyshev}$ $30$ $l=30$ $\mathrm{Chebyshev}$ $l$ $30$ .
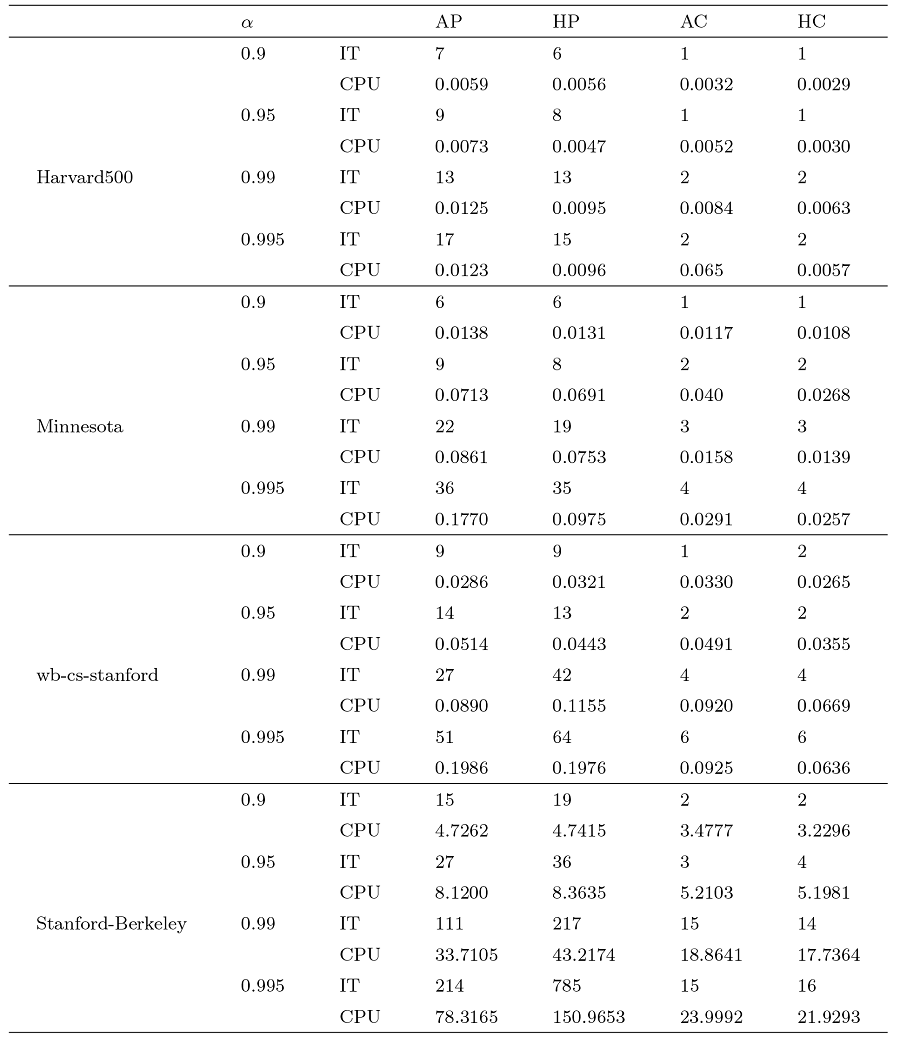
例 5.3 在本例中, 我们针对 $\mathrm{Harvard500}$ $\mathrm{Minnesota}$ $\mathrm{wb}$ - $\mathrm{cs}$ - $\mathrm{stanford}$ $\mathrm{Stanford}$ - $\mathrm{Berkeley }$ $m=10$ $l=30$ $\mathrm{AP}$ $\mathrm{HP}$ $\mathrm{AC}$ $\mathrm{HC}$ $\mathrm{IT}$ $\mathrm{CPU}$ $\alpha$
从表4 数据中可见, $\mathrm{HC}$ $\mathrm{Harvard500}$ $\mathrm{Minnesota}$ $\mathrm{wb}$ - $\mathrm{cs}$ - $\mathrm{stanford}$ $\mathrm{Stanford}$ - $\mathrm{Berkeley}$ $\mathrm{HC}$ $\mathrm{CPU}$ $\mathrm{Harvard500}$ $0.9$ $0.995$ $\mathrm{CPU}$ $1$ $2$ . 类似地, 在其他矩阵中, $\mathrm{HC}$ $\mathrm{HC}$
综上所述, $\mathrm{HC}$ $\mathrm{HC}$
6 结论
本文提出了用于计算 Google 矩阵 PageRank 向量的 Hessenberg-Chebyshev 方法, 并着重探讨了该方法的收敛性. 切比雪夫加速技术促使 Hessenberg 过程在极为宽泛的阻尼系数范围内均能出色运作, 尤其是在处理具有高阻尼系数 (尤其是接近 1 的数值) 的场景下, 展现出了显著的优势. 通过数值算例彰显了新方法相较于现有算法所具备的优越性. 此外, 我们需要着重指出的是, 这两个参数 $l$ $m$
参考文献
View Option
[1]
Page L Brin S Motwani R Winograd T . The Pagerank Citation Ranking: Bringing Order to the Web . Palo Alto : Stanford InfoLab , 1999
[本文引用: 2]
[2]
Kamvar S D Haveliwala T H Manning C D Golub G H . Extrapolation methods for accelerating PageRank computations
// Proceedings of the 12th International Conference on World Wide Web , 2003 : 261 -270
[3]
Kamvar S Haveliwala T Golub G H . Adaptive methods for the computation of PageRank
Linear Algebra Appl , 2004 , 3.6 51 -65
[4]
Langville A N Meyer C D . Deeper inside pagerank
Internet Mathematics , 2004 , 1 (3 ): 335 -380
[本文引用: 1]
[5]
Zhou T Martinez-Baez E Schenter G , et al . PageRank as a collective variable to study complex chemical transformations and their energy landscapes
The Journal of Chemical Physics , 2019 , 1.0 (13 ): 134102
[本文引用: 1]
[6]
Liu B Jiang S Zou Q . HITS-PR-HHblits: protein remote homology detection by combining PageRank and hyperlink-induced topic search
Briefings in Bioinformatics , 2020 , 21 1 ): 298 -308
[本文引用: 1]
[7]
Zhang M Li X Zhang L , et al . Boosting spectrum-based fault localization using pagerank
// Proceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis , 2017 : 261 -272
[本文引用: 1]
[8]
Heyouni M Sadok H . On a variable smoothing procedure for Krylov subspace methods
Linear Algebra and Its Applications , 1998 , 2.8 131 -149
[本文引用: 1]
[9]
Golub G H Greif C . An Arnoldi-type algorithm for computing page rank
BIT Numerical Mathematics , 2006 , 46 759 -771
[本文引用: 1]
[10]
Wu G Wei Y . A Power-Arnoldi algorithm for computing PageRank
Numerical Linear Algebra with Applications , 2007 , 14 7 ): 521 -546
[本文引用: 1]
[11]
Gu C Wang W . An Arnoldi-Inout algorithm for computing PageRank problems
Journal of Computational and Applied Mathematics , 2017 , 3.9 219 -229
[本文引用: 1]
[12]
Yin J F Yin G J Ng M . On adaptively accelerated Arnoldi method for computing PageRank
Numerical Linear Algebra with Applications , 2012 , 19 1 ): 73 -85
[本文引用: 1]
[13]
Sadok H . CMRH: A new method for solving nonsymmetric linear systems based on the Hessenberg reduction algorithm
Numer Algorithms , 1999 , 20 4 ): 303 -321
[本文引用: 1]
[14]
Gu X M Lei S L Zhang K , et al . A Hessenberg-type algorithm for computing PageRank Problems
Numerical Algorithms , 2022 , 89 4 ): 1845 -1863
[本文引用: 2]
[15]
Hu Q Y Gu X M Wen C . Application of an extrapolation method in the Hessenberg algorithm for computing PageRank
J Supercomput , 2024 , 80 15 ): 22836 -22859
[本文引用: 1]
[16]
Wrigley H E . Accelerating the Jacobi method for solving simultaneous equations by Chebyshev extrapolation when the eigenvalues of the iteration matrix are complex
Comput J , 1963 , 6 2 ): 169 -176
[本文引用: 2]
[17]
Haveliwala T H Kamvar S D . The Second Eigenvalue of the Google Matrix . Palo Alto : Stanford InfoLab , 2003
[本文引用: 1]
[18]
Miao C Q Tan X Y . Accelerating the Arnoldi method via Chebyshev polynomials for computing PageRank
J Comput Appl Math , 2020 , 3.7 : 112891
[本文引用: 1]
2
1999
... PageRank 算法被广泛用于确定网页的重要性, 是 Web 搜索中最重要的问题之一, 最早由谷歌的创始人 Larry Page 和 Sergey Brin 在一系列论文[1 4 ] 中提出. 该模型的核心思想是通过网页之间的链接关系来评估网页的重要性. 随着时间的推移, PageRank 模型已经被广泛应用于各种科学问题的分析, 包括计算化学[5 ] ,生物信息学[6 ] , 软件调试[7 ] 等领域. ...
... 在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量. ...
Extrapolation methods for accelerating PageRank computations
2003
Adaptive methods for the computation of PageRank
2004
Deeper inside pagerank
1
2004
... PageRank 算法被广泛用于确定网页的重要性, 是 Web 搜索中最重要的问题之一, 最早由谷歌的创始人 Larry Page 和 Sergey Brin 在一系列论文[1 4 ] 中提出. 该模型的核心思想是通过网页之间的链接关系来评估网页的重要性. 随着时间的推移, PageRank 模型已经被广泛应用于各种科学问题的分析, 包括计算化学[5 ] ,生物信息学[6 ] , 软件调试[7 ] 等领域. ...
PageRank as a collective variable to study complex chemical transformations and their energy landscapes
1
2019
... PageRank 算法被广泛用于确定网页的重要性, 是 Web 搜索中最重要的问题之一, 最早由谷歌的创始人 Larry Page 和 Sergey Brin 在一系列论文[1 4 ] 中提出. 该模型的核心思想是通过网页之间的链接关系来评估网页的重要性. 随着时间的推移, PageRank 模型已经被广泛应用于各种科学问题的分析, 包括计算化学[5 ] ,生物信息学[6 ] , 软件调试[7 ] 等领域. ...
HITS-PR-HHblits: protein remote homology detection by combining PageRank and hyperlink-induced topic search
1
2020
... PageRank 算法被广泛用于确定网页的重要性, 是 Web 搜索中最重要的问题之一, 最早由谷歌的创始人 Larry Page 和 Sergey Brin 在一系列论文[1 4 ] 中提出. 该模型的核心思想是通过网页之间的链接关系来评估网页的重要性. 随着时间的推移, PageRank 模型已经被广泛应用于各种科学问题的分析, 包括计算化学[5 ] ,生物信息学[6 ] , 软件调试[7 ] 等领域. ...
Boosting spectrum-based fault localization using pagerank
1
2017
... PageRank 算法被广泛用于确定网页的重要性, 是 Web 搜索中最重要的问题之一, 最早由谷歌的创始人 Larry Page 和 Sergey Brin 在一系列论文[1 4 ] 中提出. 该模型的核心思想是通过网页之间的链接关系来评估网页的重要性. 随着时间的推移, PageRank 模型已经被广泛应用于各种科学问题的分析, 包括计算化学[5 ] ,生物信息学[6 ] , 软件调试[7 ] 等领域. ...
On a variable smoothing procedure for Krylov subspace methods
1
1998
... 在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量. ...
An Arnoldi-type algorithm for computing page rank
1
2006
... 在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量. ...
A Power-Arnoldi algorithm for computing PageRank
1
2007
... 在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量. ...
An Arnoldi-Inout algorithm for computing PageRank problems
1
2017
... 在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量. ...
On adaptively accelerated Arnoldi method for computing PageRank
1
2012
... 在过去十年左右的时间里, 研究人员针对这个线性系统进行了大量的研究, 特别是在处理大规模 (即 $n$ $\alpha=0.85$ [1 ] 的解决策略已被证明是非常有效的. 然而, 当 $\alpha$ [8 ] 的 Krylov 子空间方法进行大型 PageRank 计算, 主要是由于它们的内存效率和固有的并行性. Golub 和 Greif 将改进后的 Arnoldi 过程扩展到 PageRank 上, 强制相关位移为 1, 有效规避了算法复杂性的缺陷, 从而显著提升了算法效率[9 ] . 此外, 许多技术试图将传统的 Arnoldi 方法与幂算法相结合, 以产生更快的求解器, 例如 Power-Arnoldi[10 ] 和 Arnoldi-inout[11 ] 方法. 在 Power-Arnoldi 算法中, 首先使用 Arnoldi 方法进行一定次数的迭代, 得到一个近似解. 如果这个近似解不满足要求, 就使用 Power 方法来进一步改进近似解. 这样反复迭代, 直到达到所需的精度. 在文献[12 ]中提出的技术中, 加权最小二乘问题根据残差的分量自适应地改变. 然后, 使用广义 Arnoldi 方法计算近似 PageRank 向量. ...
CMRH: A new method for solving nonsymmetric linear systems based on the Hessenberg reduction algorithm
1
1999
... 然而, 当 Krylov 子空间的维数增大时, 基于 Arnoldi 的求解器在内存和计算成本方面会显著增加. 相反, 如果维数过低, 这些方法有时可能无法有效加速基本的幂法, 特别是在阻尼系数较高时, 甚至可能出现停滞不前的情况. 为攻克这一难题, Hessenberg 于 1940 年引入海森伯格约简过程[13 ] , 并由于其较低的算术和存储需求, 该过程最近被重新启用, 以建立许多针对稀疏矩阵系统的具有成本效益的 Krylov 子空间求解器. 在此基础之上, 顾等人在 2019 年将 Hessenberg 过程与重新启动的技术相结合, 提出了 Hessenberg-type算法[14 ] 以用于计算 PageRank 向量. 胡等人在 2024 年将外推过程引入到 Hessenberg 型算法中, 得到了新的 Hessenberg-extrapolation[15 ] 算法. 本文尝试使用 Chebyshev 多项式来加速 Hessenberg 算法, 从而提出了一种新的 Hessenberg-Chebyshev 算法并详细探讨了该算法的构造和收敛性. 数值结果表明, 当阻尼因子 $\alpha$
A Hessenberg-type algorithm for computing PageRank Problems
2
2022
... 然而, 当 Krylov 子空间的维数增大时, 基于 Arnoldi 的求解器在内存和计算成本方面会显著增加. 相反, 如果维数过低, 这些方法有时可能无法有效加速基本的幂法, 特别是在阻尼系数较高时, 甚至可能出现停滞不前的情况. 为攻克这一难题, Hessenberg 于 1940 年引入海森伯格约简过程[13 ] , 并由于其较低的算术和存储需求, 该过程最近被重新启用, 以建立许多针对稀疏矩阵系统的具有成本效益的 Krylov 子空间求解器. 在此基础之上, 顾等人在 2019 年将 Hessenberg 过程与重新启动的技术相结合, 提出了 Hessenberg-type算法[14 ] 以用于计算 PageRank 向量. 胡等人在 2024 年将外推过程引入到 Hessenberg 型算法中, 得到了新的 Hessenberg-extrapolation[15 ] 算法. 本文尝试使用 Chebyshev 多项式来加速 Hessenberg 算法, 从而提出了一种新的 Hessenberg-Chebyshev 算法并详细探讨了该算法的构造和收敛性. 数值结果表明, 当阻尼因子 $\alpha$
... 在本节中, 将对用于计算 PageRank 的 Hessenberg-type 算法[14 ] 进行介绍. Hessenberg-type 算法和 Arnoldi-type算法是相似的, Hessenberg-type 算法也产生 Krylov 子空间的一组基, 但这组基不是正交的. 下面给出了计算 PageRank 的 Hessenberg-type 算法. ...
Application of an extrapolation method in the Hessenberg algorithm for computing PageRank
1
2024
... 然而, 当 Krylov 子空间的维数增大时, 基于 Arnoldi 的求解器在内存和计算成本方面会显著增加. 相反, 如果维数过低, 这些方法有时可能无法有效加速基本的幂法, 特别是在阻尼系数较高时, 甚至可能出现停滞不前的情况. 为攻克这一难题, Hessenberg 于 1940 年引入海森伯格约简过程[13 ] , 并由于其较低的算术和存储需求, 该过程最近被重新启用, 以建立许多针对稀疏矩阵系统的具有成本效益的 Krylov 子空间求解器. 在此基础之上, 顾等人在 2019 年将 Hessenberg 过程与重新启动的技术相结合, 提出了 Hessenberg-type算法[14 ] 以用于计算 PageRank 向量. 胡等人在 2024 年将外推过程引入到 Hessenberg 型算法中, 得到了新的 Hessenberg-extrapolation[15 ] 算法. 本文尝试使用 Chebyshev 多项式来加速 Hessenberg 算法, 从而提出了一种新的 Hessenberg-Chebyshev 算法并详细探讨了该算法的构造和收敛性. 数值结果表明, 当阻尼因子 $\alpha$
Accelerating the Jacobi method for solving simultaneous equations by Chebyshev extrapolation when the eigenvalues of the iteration matrix are complex
2
1963
... 在本节中, 我们尝试用 Chebyshev 加速 Hessenberg-type 算法用于计算 PageRank, 从而开发了 Hessenberg-Chebyshev 新算法. 我们使用 Chebyshev 多项式[16 ] 来改进 Hessenberg-type 算法以计算 PageRank. 假设 Google 矩阵 $A$ $1 = |\lambda_1| > |\lambda_2| \geq \cdots \geq |\lambda_n|$ . 令 $P_{l}$ $l$ $(\lambda_{i},\mu_i), i = 1, 2, \cdots, n$ $A$
... 是第一类 $l$ 16 ]. ...
1
2003
... 引理4.1 [17 ] 设 $P$ $n\times n$ $\alpha$ $0<\alpha<1$ $E$ $n\times n$ $E=ve^\top $ $e$ $1$ $n$ $v$ $1$ $n$ $A=\alpha P+(1-\alpha)E$ $A$ $\lambda_1=1$ $|\lambda_2|\le\alpha $ . ...
Accelerating the Arnoldi method via Chebyshev polynomials for computing PageRank
1
2020
... 在本节中, 我们首先讨论重启数 $m$ $l$ 18 ]中的 Arnoldi-Chebyshev (AC) 算法. 针对表3 中的矩阵进行测试, 这些矩阵可以在 https://sparse.tamu.edu/ 上下载获得, 同时也列出了这些矩阵的一些性质, 其中 $n$ $nnz$ $\text{den}=\frac{nnz}{n\times n}\times 100\% $ . ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}