1 引言
在科学计算和工程应用中, 反问题广泛存在, 其已经发展成为横跨数学, 物理, 医疗, 信号勘察等众多科学的一个热门研究领域[1 ] . 随着科技水平的提高, 实际生活的需要促使理论研究成果与丰硕的科技创新并驾齐驱, 数学物理反问题引起了众多研究者的广泛关注与深入探究[2 ] . 由于绝大多数反问题都是不适定问题, 为了得到稳定近似解必须采取正则化策略进行求解, 如变分正则化方法和迭代正则化方法[2 5] .
(1.1) $F(x)=y,$
其中 $F:\mathcal{D}(F)\subset \mathcal{X}\rightarrow \mathcal{Y}$ $\mathcal{X}$ $\mathcal{Y}$ $y$ . 在本文中, 假设问题 (1.1) 的解总是存在且算子 $F$ $\acute{\rm e}$ $y^{\delta}$ [6 ]
(1.2) $\|y^{\delta}-y\|\le \delta,$
求解问题 (1.1) 的常用方法为 Landweber 迭代正则化方法[3 ,7 ,8 ] , 其迭代格式为
(1.3) $x_{k+1}^{\delta}=x_k^{\delta}-\alpha_k^{\delta}F^{\prime}(x_{k}^{\delta})^*(F(x_k^{\delta})-y^{\delta}),$
其中 $k$ $x_0^{\delta}=x_0$ $F^{\prime}$ $F$ $\acute{\rm e}$ $*$ $F$ $\alpha_k^{\delta}$ $\alpha_k^{\delta}$ [9 ] . 在数据存在噪声的情况下, 本文采用偏差原理作为停机准则, 即
(1.4) $\|y^{\delta}-F(x_{k_*}^{\delta})\|\le \tau \delta<\|y^{\delta}-F(x_k^{\delta})\|, 0\le k <k_*, \tau>1,$
其中 $k_*$
Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ]
Nesterov 加速方案最初被引入用于求解凸规划问题, 该方案在实现上效果显著, 并大幅提升了收敛速度, 其数学框架为动量法奠定了一定的理论基础[17 ,19 ,20 ] . 此外, Hubmer和 Ramlau 在 Nesterov 加速技巧[19 ,20 ] 的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为
(1.5) $\begin{aligned}z_k^{\delta}&=x_k^{\delta}+\lambda_k^{\delta}(x_k^{\delta}-x_{k-1}^{\delta}),\\x_{k+1}^{\delta}&=z_k^{\delta}-\alpha_k^{\delta} F^{\prime}(z_k^{\delta})^*(F(z_k^{\delta})-y^{\delta}),\end{aligned}$
其中初始值 $x_0^{\delta}=x_{-1}^{\delta}=x_0$ $ \lambda_k^{\delta}>0$ 16 ]). TPG 方法通过引入前一步的迭代信息进行外推加速, 实现了对 Landweber 迭代正则化方法的加速, 但需额外计算组合参数 $\lambda_k^{\delta}$
动量法最初被用于加速梯度下降法, 在迭代算法中加入动量项, 可使得算法在迭代过程中跳出局部最优点, 快速向全局最优点靠近, 提高收敛速度[21 ,22 ] . 该方法的主要思想是利用累积动量近似当前迭代步的下降方向, 每次迭代的梯度可看作加速度[22 ] . 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一.
重球法 (HB) 通过添加动量项扩展了梯度下降法, 该动量项整合了当前迭代信息与前一步迭代信息之间的差异, 从而引导下一步迭代向解方向移动[25 ,26 ] . HB 算法不仅需要调整其动量参数, 还需优化步长, 这使得算法运行更加复杂[26 ] . 2024 年, Jin 等[27 ] 提出了自适应重球法, 其迭代格式为
(1.6) $x_{k+1}^{\delta}=x_k^{\delta}-\alpha_k^{\delta}F^{\prime}(x_k^{\delta})(F(x_k^{\delta})-y^{\delta})+\beta_k^{\delta}(x_k^{\delta}-x_{k-1}^{\delta}).$
该方法中迭代步长 $\alpha_k^{\delta}$ $\beta_k^{\delta}$
本文基于两点梯度法, 自适应重球法及动量法的思想, 考虑当前步迭代信息和前一步迭代信息对迭代解进行修正, 在下降方向引入动量项, 利用所有历史梯度信息对当前梯度进行修正, 从而得到自适应动量加速两点梯度法 (ATPGM), 迭代格式为
(1.7) $\begin{aligned}z_k^{\delta}&=x_k^{\delta}+\lambda_k^{\delta}(x_k^{\delta}-x_{k-1}^{\delta}),\\s_{k+1}^{\delta}&=\beta_k^{\delta} s_{k}^{\delta}-\alpha_k^{\delta} F^{\prime}(z_k^{\delta})^*(F(z_k^{\delta})-y^{\delta}),\\x_{k+1}^{\delta}&=z_k^{\delta}+s_{k+1}^{\delta},\end{aligned}$
其中 $s_k^{\delta}$ $\beta_k^{\delta}\in [0,1)$ $\lambda_k^{\delta}\in [0,1)$ $\alpha_k^{\delta}$ $s_k^{\delta}$ $\beta_k^{\delta}$ $\alpha_k^{\delta}$
本文的结构如下: 第 2 部分将介绍 ATPGM 方法的理论基础和算法实现; 第 3 部分将通过数值实验验证该方法的数值表现; 最后, 第 4 部分将总结研究成果.
2 收敛性分析
利用 ATPGM 迭代法求解问题 (1.1) 以获得稳定近似解, 在进行收敛性分析时, 需要以下假设.
假设 2.1 在问题 (1.1) 中, 假设非线性算子 $F$ $x_0$ $B_\rho(x_0)$ $\acute{\rm e}$
(2.1) $\|F(x)-F(\bar{x})-F^{\prime}(x)(x-\bar{x})\|\le \eta \|F(x)-F(\bar{x})\|,$
其中 $\eta\in(0,\frac{1}{2}), x, \bar{x}\in B_{4 \rho}(x_0)\subset D(F)$ $B_\rho(x_0)$ $x_0$ $\rho$
(2.2) $\alpha_k^{\delta}\|F^{\prime}(z_k^{\delta})^*(y^{\delta}-F(z_k^{\delta}))\|^2\le \|y^{\delta}-F(z_k^{\delta})\|^2.$
为了分析简化, 引入符号: $r_k^{\delta}:=F(z_k^{\delta})-y^{\delta}, g_k^{\delta}:=F^{\prime}(z_k^{\delta})^*r_k^{\delta}$ . 由假设 2.1 和假设 2.2, 可以证明如下命题[6 ] .
命题 2.1 步假设 2.1 和假设 2.2 成立, 且 $F(x)=y$ $x_*\in B_{\rho}(x_0)=B_{\rho}(x_{-1})$ . 设 $x_{k}^{\delta},x_{k-1}^{\delta}\in B_{\rho}(x_*)$
(2.3) $\|y^{\delta}-F(z_k^{\delta})\|>\tau \delta,$
有 $\tau>2\frac{1+\eta}{1-2\eta}$
(2.4) $\Delta_{k+1}:=\|x_{k+1}^{\delta}-x_*\|^2-\|x_{k}^{\delta}-x_*\|^2,$
(2.5) $c_0:=(1-2\eta)-2(1+\eta)\tau^{-1}>0,$
(2.6) $\begin{aligned}\Delta_{k+1}&\le \lambda_k^{\delta}\Delta_k+\lambda_k^{\delta}(\lambda_k^{\delta}+1)\|x_k^{\delta}-x_{k-1}^{\delta}\|^2-(1+c_0)\alpha_k^{\delta}\|r_k^{\delta}\|^2+(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2\\& +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta}\rangle +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle.\end{aligned}$
证 因为 $x_{k}^{\delta},x_{k-1}^{\delta}\in B_{\rho}(x_*),$ $x_{*}^{\delta}\in B_{\rho}(x_0),$ $x_{k}^{\delta},x_{k-1}^{\delta}\in B_{2\rho}(x_0),$ $\lambda_k^{\delta}< 1$
故 $z_k^{\delta}\in B_{4\rho}(x_0)$ . 利用 (1.2) 式, (2.1) 式, (2.3) 式, (2.5) 式, 得到
(2.7) $\begin{aligned}& \|x_{k+1}^{\delta}-x_*\|^2-\|z_k^{\delta}-x_*\|^2\\&=\|x_{k+1}^{\delta}-z_k^{\delta}\|^2+2 \langle x_{k+1}^{\delta}-z_k^{\delta},z_k^{\delta}-x_* \rangle\\&=\|-\alpha_k^{\delta}\cdot g_k^{\delta}+\beta_k^{\delta} s_{k}^{\delta}\|^2-2 \langle \alpha_k^{\delta}\cdot g_k^{\delta}-\beta_k^{\delta} s_{k}^{\delta},z_k^{\delta}-x_* \rangle\\&=(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2+(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta}\rangle+2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle\\& +2\alpha_k^{\delta} \langle F^{\prime}(z_k^{\delta})^*(y^{\delta}-F(z_k^{\delta})),z_k^{\delta}-x_* \rangle \\&\le (\alpha_k^{\delta})^2\|g_k^{\delta}\|^2+(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta} \rangle+2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_*\rangle -(c_0+1)\alpha_k^{\delta}\|r_k^{\delta}\|^2,\end{aligned}$
(2.8) $\begin{aligned}\label{2.8} \Delta_{k+1} &=\|x_{k+1}^{\delta}-x_*\|^2-\|x_{k}^{\delta}-x_*\|^2 \notag\\ &\le \|z_k^{\delta}-x_*\|^2-\|x_{k}^{\delta}-x_*\|^2-(c_0+1)\alpha_k^{\delta}\|r_k^{\delta}\|^2+(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2 \notag\\ & +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta} \rangle +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle \notag\\ &=(\lambda_k^{\delta})^2\|x_k^{\delta}-x_{k-1}^{\delta}\|^2-2 \lambda_k^{\delta}\langle x_{k-1}^{\delta}-x_k^{\delta},x_k^{\delta}-x_* \rangle -(c_0+1)\alpha_k^{\delta}\|r_k^{\delta}\|^2 \notag\\ & +(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2 +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta} \rangle +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle \notag\\ &=(\lambda_k^{\delta})^2\|x_k^{\delta}-x_{k-1}^{\delta}\|^2-\lambda_k^{\delta}(\|x_{k-1}^{\delta}-x_k^{\delta}+x_k^{\delta}-x_*\|^2-\|x_k^{\delta}-x_{k-1}^{\delta}\|^2-\|x_k^{\delta}-x_*\|^2) \notag\\ & -(c_0+1)\alpha_k^{\delta}\|r_k^{\delta}\|^2+(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2 +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta} \rangle +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle \notag\\ &=-\lambda_k^{\delta}(\|x_{k-1}^{\delta}-x_*\|^2-\|x_k^{\delta}-x_*\|^2)+\lambda_k^{\delta}(\lambda_k^{\delta}+1)\|x_k^{\delta}-x_{k-1}^{\delta}\|^2-(c_0+1)\alpha_k^{\delta}\|r_k^{\delta}\|^2 \notag\\ & +(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2 +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta} \rangle +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle \notag\\ &\le \lambda_k^{\delta}\Delta_k+\lambda_k^{\delta}(\lambda_k^{\delta}+1)\|x_k^{\delta}-x_{k-1}^{\delta}\|^2-(c_0+1)\alpha_k^{\delta}\|r_k^{\delta}\|^2+(\alpha_k^{\delta})^2\|g_k^{\delta}\|^2 \notag\\ & +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta} \rangle +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle. \end{aligned}$
为了获得一种收敛的方法, 需要找到合适的 $\alpha_k^{\delta}$ $\beta_k^{\delta}$ $(\alpha_k^{\delta})^2||g_k^{\delta}||^2-\alpha_k^{\delta}||r_k^{\delta}||^2 \le 0$ . 由此可以选择 $\alpha_k^{\delta}$
(2.9) $\alpha_k^{\delta}=\min\Big\{\frac{\mu_0\|F(z_k^{\delta})-y^{\delta}\|^2}{\|F^{\prime}(z_k^{\delta})*(y^{\delta}-F(z_k^{\delta}))\|^2},\mu_1\Big\},$
其中 $\mu_0,\mu_1$ $\mu_0\in (0,1]$ $\mu_1$ $[\mu_1]$ $\alpha_k^{\delta}$ . 将 (2.9) 式中的 $\alpha_k^{\delta}$
(2.10) $\begin{aligned}\label{2.10} \Delta_{k+1} &\le \lambda_k^{\delta}\Delta_k+\lambda_k^{\delta}(\lambda_k^{\delta}+1)\|x_k^{\delta}-x_{k-1}^{\delta}\|^2\notag-c_0\alpha_k^{\delta}\|r_k^{\delta}\|^2 \notag\\ & +2\beta_k^{\delta}\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle +(\beta_k^{\delta})^2\|s_{k}^{\delta}\|^2-2\alpha_k^{\delta}\beta_k^{\delta} \langle g_k^{\delta}, s_{k}^{\delta}\rangle. \end{aligned}$
下面考虑 $\beta_k^{\delta}$ $\bar{\beta}\in (0,1)$ $[\bar{\beta}]$ $\|s_k^{\delta}\|\neq 0$
$$\beta_{k}^{\delta}=\min\Big\{\max\Big\{0,\frac{\alpha_k^{\delta} \langle g_k^{\delta},s_{k}^{\delta} \rangle -\langle s_{k}^{\delta},z_k^{\delta}-x_* \rangle}{\|s_{k}^{\delta}\|^2}\Big\},\bar{\beta}\Big\}.$$
显然该计算表达式中涉及到了未知解 $x_*$ $\beta_{k}^{\delta}$
(2.11) $\gamma_k^{\delta}:=\langle s_k^{\delta},z_k^{\delta}-x_* \rangle.$
当 $\gamma_0^{\delta}=0$ $k\ge 1$ $z_{k-1}^{\delta}\in B_{4\rho}(x_0)$
(2.12) $\begin{aligned}\gamma_k^{\delta}&=\langle s_k^{\delta},z_k^{\delta}-z_{k-1}^{\delta}\rangle+\langle s_k^{\delta},z_{k-1}^{\delta}-x_*\rangle\\&=\langle s_k^{\delta},z_k^{\delta}-z_{k-1}^{\delta}\rangle+\langle \beta_{k-1}^{\delta} s_{k-1}^{\delta}-\alpha_{k-1}^{\delta} g_{k-1}^{\delta},z_{k-1}^{\delta}-x_*\rangle\\&\le \langle s_k^{\delta},z_k^{\delta}-z_{k-1}^{\delta}\rangle+ \beta_{k-1}^{\delta}\gamma_{k-1}^{\delta}-(1-\eta)\alpha_{k-1}^{\delta}\|r_{k-1}\|^2+(1+\eta)\alpha_{k-1}^{\delta}\delta \|r_{k-1}^{\delta}\|.\end{aligned}$
(2.13) $\tilde{\gamma}_{k}^{\delta}=\langle s_{k}^{\delta},z_k^{\delta}-z_{k-1}^{\delta} \rangle -(1-\eta)\alpha_{k-1}\|r_{k-1}\|^2+\beta_{k-1}^{\delta}\tilde{\gamma}_{k-1}^{\delta}+(1+\eta)\alpha_{k-1}\delta\|r_{k-1}^{\delta}\|.$
因此选择 (2.13) 式的 $\tilde{\gamma}_{k}^{\delta}$ $\gamma_k^{\delta}$
为了收敛性分析, 假设 $x^{\dagger}$ $F(x)=y$ $x_0$
$$ x^{\dagger}-x_0\in \mathcal{N}(F^{\prime}(x^{\dagger}))^{\perp}.$$
采用关于 $z_k^{\delta}$ $x_k^{\delta}$ [28 ] . 记满足不等式 (2.14) 的最小整数为 $k_*=k_*(\delta,y^{\delta})$ .
(2.14) $\|F(z_{k_*}^{\delta})-y^{\delta}\|\le \tau \delta < \|F(z_k^{\delta})-y^{\delta}\|, 0\le k<k_*, \tau>1.$
其中 $z_{k_*}^{\delta}$ $x^{\dagger}$
![]()
在算法 1 中,使用 (2.14) 式作为停机准则 (或偏差原理), 即迭代将在 $k_*$ $0\le k\le k_*$ $\gamma_{k+1}^{\delta}\le \tilde{\gamma}_{k+1}^{\delta}$ .
假设存在 $l<k_*$ $\forall 0 \le k \le l$ $\beta_l^{\delta}\ge 0$
记 $h_l(t):=(t)^2\|s_{l}^{\delta}\|^2-2\alpha_l^{\delta}t\langle g_l^{\delta}, s_{l}^{\delta} \rangle +2t\tilde{\gamma}_l^{\delta}.$ $\beta_{l}^{\delta}$ $t\rightarrow h_l(t)$ $[\bar{\beta}]$
(2.15) $\begin{aligned}\label{2.15} \Delta_{l+1}&\le \lambda_l^{\delta}\Delta_l+\lambda_l^{\delta}(\lambda_l^{\delta}+1)\|x_l^{\delta}-x_{l-1}^{\delta}\|^2-c_0\alpha_l^{\delta}\|r_l^{\delta}\|^2+h_l(\beta_{l}^{\delta}) \\ &\le \lambda_l^{\delta}\Delta_l+\lambda_l^{\delta}(\lambda_l^{\delta}+1)\|x_l^{\delta}-x_{l-1}^{\delta}\|^2-c_0\alpha_l^{\delta}\|r_l^{\delta}\|^2+h_l(0) \\ &=\lambda_l^{\delta}\Delta_l+\lambda_l^{\delta}(\lambda_l^{\delta}+1)\|x_l^{\delta}-x_{l-1}^{\delta}\|^2-c_0\alpha_l^{\delta}\|r_l^{\delta}\|^2. \end{aligned}$
对于 $\forall l< k_*$ $x_{l+1}^{\delta}$ $x_l^{\delta}$ $x_*$ . 因此, 根据 (2.15) 式, 使用以下耦合条件
(2.16) $\lambda_l^{\delta}(\lambda_l^{\delta}+1)\|x_l^{\delta}-x_{l-1}^{\delta}\|^2-\frac{c_0}{\mu}\alpha_l^{\delta}\|r_l^{\delta}\|^2\le 0,$
这对所有 $0\le l<k_*$ $k_*$ $\mu$ [16 ] , 利用归纳假设法推导 $\Delta_{l+1}\le 0$ .
命题 2.2 假设 2.1 和假设 2.2 成立, 且方程 $F(x) = y$ $B_\rho(x_0)=B_\rho(x_{-1})$ $x_*$ . $k_*$ $0\le l<k_*$
$$\|x_{l+1}^{\delta}-x_*\|\le \|x_l^{\delta}-x_*\|, \forall -1\le l<k_*.$$
此外, 对任意的 $ x_l^{\delta}\in B_\rho(x_*)\subset B_{2\rho}(x_0),-1\le l<k_*$
(2.17) $\Big(\min\limits_{0\le k \le l< k_*}{\alpha_k^{\delta}} \Big)k_*(\tau \delta)^2 \le \sum\limits_{l=0}^{k_*-1} \alpha_k^{\delta} \|r_l^{\delta}\|^2\le (\bar{\mu}c_0)^{-1}\|x_0^{\delta}-x_*\|^2, \bar{\mu}=\frac{\mu -1}{\mu}.$
注 2.1 $\lambda_0^{\delta}=0, \lambda_l^{\delta}\ge 0,x_0^{\delta}=x_{-1}^{\delta}=x_0.$
证 由 (2.15) 式可知, 当 $l = 0$
(2.18) $\begin{aligned}\label{2.18} \Delta_1 &\le \lambda_0^{\delta}\Delta_0+\lambda_0^{\delta}(\lambda_0^{\delta}+1)\|x_0^{\delta}-x_{-1}^{\delta}\|^2-c_0\alpha_0^{\delta}\|r_0^{\delta}\|^2\notag\\ &\le \frac{c_0}{\mu}\alpha_0^{\delta}\|r_0^{\delta}\|^2-c_0\alpha_0^{\delta}\|r_0^{\delta}\|^2=-\bar{\mu}c_0 \alpha_0^{\delta}\|r_0^{\delta}\|^2\le 0. \end{aligned}$
由此有 $x_1^{\delta}\in B_\rho (x_*)$ . 假设 $\Delta_l^{\delta}\le 0$ $\Delta_{l+1}^{\delta}\le 0$
(2.19) $\begin{aligned}\Delta_{l+1}^{\delta}&\le \lambda_l^{\delta}\Delta_l+\lambda_l^{\delta}(\lambda_l^{\delta}+1)\|x_l^{\delta}-x_{l-1}^{\delta}\|^2-c_0\alpha_l^{\delta}\|r_l^{\delta}\|^2\\&\le \frac{c_0}{\mu}\alpha_l^{\delta}\|r_l^{\delta}\|^2-c_0\alpha_l^{\delta}\|r_l^{\delta}\|^2=-\bar{\mu}c_0 \alpha_l^{\delta}\|r_l^{\delta}\|^2\le 0.\end{aligned}$
由此有 $x_{l+1}^{\delta}\in B_\rho(x_*)\subset B_{2\rho}(x_0)$
(2.20) $\bar{\mu}c_0\alpha_l^{\delta}\|r_l^{\delta}\|^2\le \|x_l^{\delta}-x_*\|^2-\|x_{l+1}^{\delta}-x_*\|^2,$
(2.21) $\begin{aligned}\label{2.24} \sum_{l=0}^{k_*-1}\bar{\mu}\alpha_l^{\delta}\|r_l^{\delta}\|^2 &\le \|x_0^{\delta}-x_*\|^2-\|x_{k_*}^{\delta}-x_*\|^2 \le \|x_0^{\delta}-x_*\|^2. \end{aligned}$
(2.22) $\Big(\min\limits_{0\le k \le l< k_*}{\alpha_k^{\delta}}\Big)k_*(\tau \delta)^2\le \sum_{l=0}^{k_*-1} \alpha_l^{\delta} \|r_l^{\delta}\|^2\le (\bar{\mu}c_0)^{-1}\|x_0^{\delta}-x_*\|^2.$
$$k_*\le (\min\limits_{0\le k \le l< k_*}{\alpha_k^{\delta}})^{-1}\frac{||x_0^{\delta}-x_*||^2}{\bar{\mu}c_0(\tau \delta)^2}.$$
在精确数据 $y^{\delta}=y$ $\delta=0$ ) 下, (2.17) 式意味着 $k_*=\infty$
(2.23) $\sum_{k=0}^{\infty} \alpha_k\|r_k\|^2 <\infty.$
该结论仅在 $F(z_k)\neq y$ $k\in N$ ) 时成立, 否则求和运算会在有限步后终止. 但这并不是限制条件, 因为若存在某个 $k$ $F(z_k)= y$
(2.24) $\sum_{k=0}^{\infty}\lambda_k^0(\lambda_k^0+1)\|x_k-x_{k-1}\|^2 <\infty, \sum_{k=0}^{\infty}(\alpha_k)^2\|g_k\|^2<\infty.$
(2.25) $\begin{aligned}\lim\limits_{k\rightarrow\infty}\alpha_k\|r_k\|^2=0, \lim\limits_{k\rightarrow \infty}\lambda_k^0(\lambda_k^0+1)\|x_k-x_{k-1}\|^2=0, \lim\limits_{k\rightarrow \infty}(\alpha_k)^2\|g_k\|^2=0.\end{aligned}$
如果 $\alpha_k^{\delta}$
(2.26) $0<\alpha_{\min}^{\delta}=\min_{k\in N}\{\alpha_k\},$
(2.27) $\lim_{k\rightarrow \infty}\|r_k\|=\lim_{k\rightarrow \infty}\|y-F(z_k)\|=0.$
命题 2.3 设 $x_*$ $F(x)=y$ $x_k$ $\delta=0$ . 假设当 $k\rightarrow \infty$ $\|x_k-x_*\|\rightarrow \varepsilon, \varepsilon\ge 0$ $k\rightarrow \infty$ $\lambda_k^0\|x_k-x_{k-1}\|\rightarrow 0$ $\|s_{k+1}\|\rightarrow 0$ [16 ]
$$ \lim\limits_{k\rightarrow \infty}\|z_k-x_*\|=\varepsilon.$$
证 使用 (1.7) 式的定义以及夹逼原则容易证明该结论. 可参考文献 [16 ].
对组合参数 $\lambda_k^0$
(2.28) $\sum_{k=0}^{\infty}\lambda_k^0\|x_k-x_{k-1}\|<\infty.$
由于 $\|x_k-x_{k-1}\| \le 2\rho$
(2.29) $\sum\limits_{k=0}^{\infty}\lambda_k^0<\infty.$
这意味着当 $k\rightarrow\infty$ $\lambda_k^0\rightarrow 0$ $\delta = 0$ 16 ,定理 2.8] 和文献 [27 ,定理 3.5] 证明类似, 可以证明定理 2.1 中精确数据的收敛性.
定理 2.1 假设 2.1 和假设 2.2 成立且 $F(x)=y$ $x_*\in B_{\rho}(x_0)=B_{\rho}(x_{-1})$ . 设 $k_*=k_*(0,y)=\infty$ $\forall k\in N$ $y^{\delta}=y$ $z_k$ $F(x)=y$ $0<\bar{\beta}<1$ . 如果对所有 $x\in B_{4\rho}(x^{\dagger})$ $N(F^{\prime}(x^{\dagger}))\subset N(F^{\prime}(x)),$ $k\rightarrow \infty $ $z_k\rightarrow x^{\dagger}$ .
证 定义 $e_k:=z_k-x_*$ . 由命题 2.2 知 $\|x_k-x_*\|\rightarrow \varepsilon\ge 0,$ $\|e_k\|$ $\varepsilon$ . 接下来证明 $\{e_k\}$ $j\ge k,$ $l$ $k$ $j$
(2.30) $\|y-F(z_l)\|\le \|y-F(z_i)\|, \forall k\le i\le j,$
(2.31) $\|e_j-e_k\|\le \|e_j-e_l\|+\|e_l-e_k\|,$
(2.32) $\begin{aligned}&\|e_j-e_l\|^2=2 \langle e_l-e_j,e_l \rangle +\|e_j\|^2-\|e_l\|^2,\\&\|e_l-e_k\|^2=2 \langle e_l-e_k,e_l \rangle+\|e_k\|^2-\|e_l\|^2.\end{aligned}$
当 $k\rightarrow \infty$ $\varepsilon^2-\varepsilon^2=0$ . 接着证明当 $k\rightarrow \infty$ $\langle e_l-e_k,e_l\rangle $ $\langle e_l-e_j,e_l \rangle$
(2.33) $\begin{aligned}& |\langle e_l-e_k,e_l\rangle|=|\langle z_l-z_k,e_l\rangle|\\&=|\langle x_l-x_k+\lambda_l^0(x_l-x_{l-1})-\lambda_k^0(x_k-x_{k-1}),e_l\rangle|\\&\le |\langle x_l-x_k,e_l\rangle|+\lambda_l^0|\langle x_l-x_{l-1},e_l\rangle|+\lambda_k^0|\langle x_k-x_{k-1},e_l\rangle |\\&\le |\langle x_l-x_k,e_l\rangle |+\lambda_l^0\|x_l-x_{l-1}\|\|e_l\|+\lambda_k^0|\|x_k-x_{k-1}\|\|e_l\|.\end{aligned}$
使用 (2.25) 式以及 $\|e_k\|\rightarrow \varepsilon$
(2.34) $\begin{aligned}\label{2.34} \lim\limits_{k\rightarrow \infty}(\lambda_l^0\|x_l-x_{l-1}\|\|e_l\|+\lambda_k^0\|x_k-x_{k-1}\|\|e_l\|)=0. \end{aligned}$
$$x_k=x_0+\sum\limits_{n=0}^{k-1}\lambda_n^{0}(x_k-x_{k-1})+\sum\limits_{n=k}^{k-1}s_{n+1},$$
(2.35) $\begin{aligned}|\langle x_l-x_k,e_l\rangle|&=\Big| \Big\langle \sum_{n=k}^{l-1}\lambda_n^0(x_n-x_{n-1})+\sum_{n=k}^{l-1}s_{n+1},e_l\Big\rangle \Big|\\&\le \sum_{n=k}^{l-1}\lambda_n^0\Big| \langle x_n-x_{n-1},e_l\rangle \Big|+\sum_{n=k}^{l-1}\Big|\langle s_{n+1},e_l \rangle\Big|.\end{aligned}$
利用 Cauchy-Schwarz 不等式及 $0\le \beta_n\le \bar{\beta}, \forall n\ge 0$
(2.36) $\begin{aligned}\label{2.36} \Big|\sum_{n=k}^{l-1}\langle s_{n+1},e_l\rangle \Big| &=\sum_{n=k}^{l-1}\Big|\Big\langle \sum_{i=0}^{n}\beta_i^{n-i} \alpha_i F^{\prime}(z_i)^*(y-F(z_i)),e_l\Big\rangle \Big|\notag\\ &\le \sum_{n=k}^{l-1}\sum_{i=0}^n \beta_i^{n-i} \alpha_i\|y-F(z_i)\|\|F^{\prime}(z_i)(z_l-x_*)\|\notag\\ &\overset{ (8)}{\le} \sum_{n=k}^{l-1}\sum_{i=0}^n \beta_i^{n-i} \alpha_i\|y-F(z_i)\| \big(2\eta\|F(z_i)-y\|+(\eta+1)\|F(z_l)-y\|\big)\notag\\ &\overset{ (32)}{\le} (1+3\eta)\sum_{n=k}^{l-1}\sum_{i=0}^n \beta_i^{n-i} \alpha_i\|y-F(z_i)\|^2 \notag\\ &\le (1+3\eta)\sum_{n=k}^{l-1}\sum_{i=0}^n \bar{\beta}^{n-i} \alpha_i\|y-F(z_i)\|^2. \end{aligned}$
$$M_K=\sum\limits_{n=0}^{K}\sum\limits_{i=0}^n \bar{\beta}^{n-i} \alpha_i\|y-F(z_i)\|^2, \forall K\ge 0.$$
对 $M_k$ $0<\bar{\beta}<1$
因此, $\{M_K\}$ $\{M_K\}$
$$\lim\limits_{k\rightarrow \infty}\sup\limits_{l\ge k}|M_{l-1}-M_{k-1}|=0.$$
$$|M_{l-1}-M_{k-1}|=\sum\limits_{n=k}^{l-1}\sum\limits_{i=0}^n\bar{\beta}^{n-i} \alpha_i\|y-F(z_i)\|^2,$$
$$ \sup\limits_{l\ge k}\Big|\sum\limits_{n=k}^{l-1}\langle s_{n+1},e_l\rangle \Big|\le 3(1+\eta)\sup\limits_{l\ge k}|M_{l-1}-M_{k-1}|\rightarrow 0.$$
$$ \sum_{n=k}^{l-1}\lambda_n^0|\langle x_n-x_{n-1},e_l \rangle| \le \sum_{n=k}^{l-1}\lambda_n^0\|x_n-x_{n-1}\|\|e_l\| \le \sum_{n=k}^{\infty}\lambda_k^0||x_n-x_{n-1}\|\|e_l\|.$$
因为 $\|e_l\|$
$$ \lim\limits_{k\rightarrow \infty}\Big(\sum_{n=k}^{l-1}\lambda_n^0\big|\langle x_n-x_{n-1},e_l\rangle \big|\Big)=0.$$
那么当 $k\rightarrow \infty$ $|\langle x_l-x_k,e_l\rangle|\rightarrow 0$ $|\langle e_l-e_k,e_l\rangle|\rightarrow 0$ . 同理 $|\langle e_l-e_j,e_l\rangle|\rightarrow 0$ . 因此可得
$$\lim\limits_{k\rightarrow \infty}\|e_j-e_k\|=0.$$
故在 Hilbert 空间 $\mathcal{X}$ $\{e_k\}$ $\{z_k\}$ $\|F(z_k)-y\|\rightarrow 0$ $z_k$ $F(x)=y$
对所有 $x\in B_{4\rho}(x^{\dagger})$ $N(F^{\prime}(x^{\dagger}))\subset N(F^{\prime}(x))$
$$z_k-z_0=\sum_{n=0}^{k-1}(z_{n+1}-z_n)=\sum_{n=0}^{k-1}((1+\lambda_{n+1}^0)s_{n+1}+\lambda_{n+1}^0 \lambda_n^0(x_n-x_{n-1})).$$
显然 $(1+\lambda_{n+1}^0)s_{n+1}\in R(F^{\prime}(z_n)^*)$
$$R(F^{\prime}(z_n)^*)\subset N(F^{\prime}(z_n))^{\perp}\subset N(F^{\prime}(x^{\dagger}))^{\perp}, \forall n\in N.$$
$$\sum\limits_{n=0}^{k-1}(1+\lambda_{n+1}^0)s_{n+1}\in N(F^{\prime}(x^{\dagger}))^{\perp},$$
$$\sum\limits_{n=0}^{k-1}\lambda_{n+1}^0 \lambda_n^0(x_n-x_{n-1})\in N(F^{\prime}(x^{\dagger}))^{\perp}.$$
$$ z_k-z_0\in N(F^{\prime}(x^{\dagger}))^{\perp}, \forall k\in N.$$
因为对于 $z_k$ $x^{\dagger}$ $z_k\rightarrow x^{\dagger}, k\rightarrow \infty$ .
根据定理 2.1 的结论, 可以进一步推导出在相同的假设条件下, 迭代序列 $\{x_k\}$ $x_*$ $\{x_k\}$ $\{z_k\}$ $\delta=0$ $\delta\neq 0$ [16 ,22 ] .
定理 2.2 假设 2.1 和假设 2.2 成立且 $F(x)=y$ $x_*\in B_{\rho}(x_0)=B_{\rho}(x_{-1})$ . 假设 (2.16) 式成立 ($\forall 0\le k<k_*$ ). $k_*=k_*(\delta,y^{\delta})$ $0\le \lambda_k^{\delta}<1$ $\alpha_k^{\delta}$ $\lambda_k^{\delta}\rightarrow \lambda_k^0( \delta\rightarrow 0)$ . 由 (1.7) 式定义的迭代解 $z_{k_*}^{\delta}$ $F(x)=y(\delta\rightarrow 0)$ $x\in B_{4\rho}(x^{\dagger}), N(F^{\prime}(x^{\dagger})) \subset N(F^{\prime}(x))$ $z_{k_*}^{\delta}\rightarrow x^{\dagger}(\delta\rightarrow 0)$ .
证 设 $x_*$ $y$ $z_k$ $n\rightarrow \infty$ $\{\delta_n\}$ $0$ $y_n:=y^{\delta_n}$ $\|y-y_n\|\le \delta_n$ . 应用序对 $(\delta_n,y_n)$ $k_n:=k_*(\delta_n,y_n)$ .
1. 假设 $k$ $k_n$ $\forall n\in N, k_n=k$ . 因此, 从偏差原理的定义可知
$$\|y_n-F(z_k^{\delta_n})|\le \tau \delta.$$
当 $k$ $z_k^{\delta}$ $y^{\delta}$
$$z_k^{\delta_n}\rightarrow z_k, F(z_k^{\delta_n})\rightarrow F(z_k)=y, n\rightarrow \infty.$$
因此, 迭代会在 $z_k=x_*$ $z_{k_n}^{\delta_n}\rightarrow x_*, \delta_n\rightarrow 0;$
2. 假设 $n\rightarrow \infty$ $k_n\rightarrow \infty$ . 对于某个 $k$ $k_n>k+1$ $0\le \lambda_k^{\delta}< 1$
设定某个 $\varepsilon>0$ $k=k(\varepsilon)$ $\|x_{k}-x_*\|\le \frac{\varepsilon}{6}.$ $k$ $n=n(\varepsilon,k)$ $\|x_{k}^{\delta_n}-x_k\|\le \frac{\varepsilon}{6}, \forall n>n(\varepsilon,k).$ $n$ $k_n>k+1$
$$\|z_{k_n}^{\delta_n}-x_*\|\le 3\|x_k^{\delta}-x_*\| \le 3\|x_k^{\delta_n}-x_k\|+3\|x_k-x_*\|\le 3\frac{\varepsilon}{6}+3\frac{\varepsilon}{6}=\varepsilon.$$
所以 $z_{k_n}^{\delta_n}\rightarrow x_*$ ( $n\rightarrow \infty$ ).
如果 $N(F^{\prime}(x^{\dagger}))\subset N(F^{\prime}(x)), \forall x\in B_{4\rho}(x^{\dagger})$ $x_*$ $x^{\dagger}$ $z_k\rightarrow x^{\dagger}$ $x_k\rightarrow x^{\dagger}$
3 数值实验
在本节中, 采用文献 [22 ] 中的数值实验例子, 即一维和二维的椭圆方程参数识别反问题进行数值模拟展示所提出的 ATPGM 迭代法, 相较于 Landweber 迭代正则化方法和 TPG 方法的加速效果. 首先给出这些方法的简要描述.
(1) Landweber: Landweber 迭代正则化方法见 (1.3) 式;
(2) TPG: 两点梯度方法见 (1.5) 式, 选择最初的组合参数, $\lambda_k^{\delta}=\frac{k-1}{k+\alpha-1},\alpha=4$
(3) ATPGM: 自适应动量加速两点梯度法见 (1.7) 式, 动量系数 $\beta_k^{\delta}$ $\lambda_k^{\delta}=\frac{k-1}{k+\alpha-1},\alpha=4$ .
注 3.1 为使 ATPGM 迭代法具有更好的加速效果, 可选择满足 (2.28) 式的 $\lambda_k^{\delta}$ $\lambda_k^{\delta}$ .
Landweber 迭代正则化方法的收敛性在文献 [3 ,7 ,8 ] 中有详细说明. 本文实验中, 三种方法选取统一的修正步长
(3.1) $\alpha_k^{\delta}=\min\Big\{\frac{\mu_0\|F(x_k^{\delta})-y^{\delta}\|^{p(r-1)}}{\|F^{\prime}(x_k^{\delta})*(y^{\delta}-F(x_k^{\delta}))\|^p},\mu_1\Big\}\|F(x_k^{\delta})-y^{\delta}\|^p.$
其中 $\mu_0,\mu_1,p,r$
在实验中: $\mu_0=1.8 (1-\frac{1}{\tau})/\omega, \omega\text{为正常数},p=2,r=2$ . 为了统一定量分析方法的计算效率和精度上的重构性能, 本文将从算法的计算时间 (Time), 迭代停止次数 (N) 以及模型相对误差($ERR=\frac{\|x_{N_{x^*}}-x^*\|}{\|x^*\|}$ ) 等三个方面对上述三种方法进行综合对比.
注意, 为了保证 ATPGM 迭代法数据残差 $\|y^{\delta}-F(z_k^{\delta})\|$ [22 ] .
3.1 椭圆参数识别
(3.2) $\begin{cases}-\Delta u+cu=f \mbox{在} \Omega \mbox{上},\\u=g \mbox{在} \partial\Omega \mbox{上}.\\\end{cases}$
从 $u$ $\Omega\subset R^d,d\le 3$ $f\in L^{2}(\Omega)$ $g\in H^{\frac{3}{2}}(\Omega)$ . 在这个例子中, 非线性算子 $F$ $c^{\dagger} \in L^2(\Omega)$ $u=u(c^{\dagger}) \in H^ 1(\Omega)\subset L^ 2(\Omega)$ $F(c):= u(c)$ . 对任意 $c\in \mathcal{D}(F)$ $\gamma_0>0$ $F$ $\mathcal{D}(F)$
$$\mathcal{D}(F):=\{c\in L^2(\Omega):\|c-\bar{c}\|_{L^2(\Omega)}\le \gamma_0,\forall\bar{c}\ge 0\}.$$
从文献 [3 ] 可知, $F$ $F$ $\acute{\rm e}$ $h,\sigma\in L^ 2(\Omega)$
$$F^{\prime}(c)h=v \text{和} F^{\prime}(c)^*\sigma=-u(c)w,$$
其中 $v,w\in H^ 1(\Omega)$
例 3.1 $\textbf{一维椭圆方程参数识别问题}$
考虑 $\Omega = [0,1],u(0) = 1$ $u(1) = 6$
$$c^{\dagger}(\zeta)=5\zeta(1-\zeta^4)+\sin(6\pi \zeta),$$
且 $f(\zeta)=c^{\dagger}(\zeta)(1+5c^{\dagger}(\zeta))$ .
使用噪声水平 $\delta = \|u^{\delta}-u(c^{\dagger})\|>0$ $u^{\delta}$ $u^{\delta}$ $c$ . 此时, 问题 (1.1) 中所求参数 $x$ $c(\zeta)$ $x_k^{\delta}=c_k^{\delta}$ . 步长按照修正步长 (3.1) 式选取, 偏差原理 (2.14) 式的参数 $\tau=2.1$ . 对于 ATPGM 迭代法, 动量初始值 $s_0=0$ . 设迭代初始值 $c_0=0$ $\eta=0.01,\omega=30, \mu_1=1000$ . 当噪声水平 $\delta=0$ $\|u^{\delta}-F(c_k^{\delta})\|\le 0.001$ $\delta\neq 0$ $[0,1]$ $1$ $1$ $0$ . 通过实验可知动量系数 $\beta_k^{\delta}$ $[0,0.5]$ $\beta_k^{\delta}$ $\bar{\beta}=0.5$
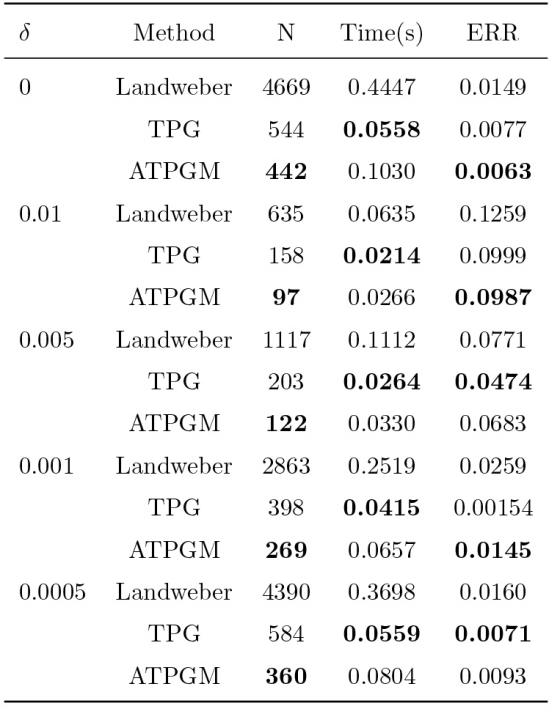
选择不同的噪音水平 $\delta$ 表1 所示. 从表1 可知, 在同一噪声水平下, ATPGM 迭代法和 TPG 方法在减少迭代次数和迭代运行时间方面明显优于 Landweber 迭代正则化方法. 其中 ATPGM 迭代法迭代运行时间略高于 TPG 方法, 可能是由于迭代步的增加, ATPGM 迭代法的动量项累积, 以及每一次迭代更新动量系数 $\beta_k^{\delta}$
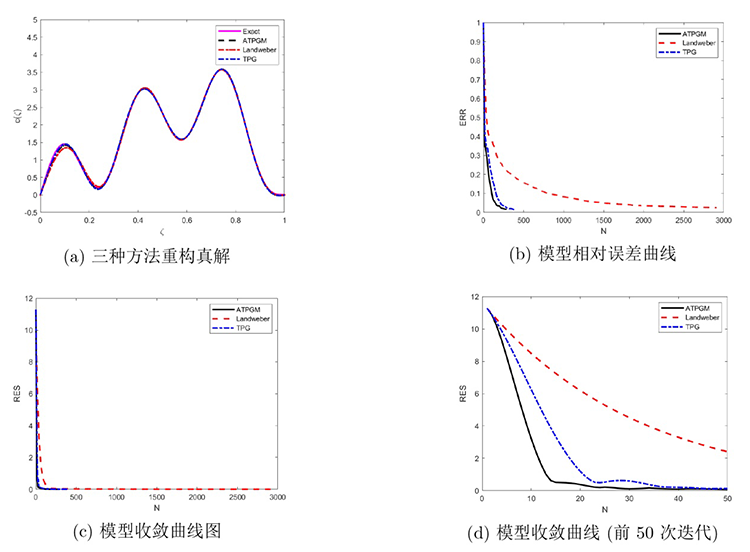
图1 展示了噪音水平 $\delta=0.001$ 图1(a) 可知, 三种方法均能有效模拟真解. 由图1(b) 和图1(c) 可知, TPG 方法和 ATPGM 迭代法收敛速度明显快于 Landweber 迭代正则化方法, 且 ATPGM 迭代法略快于 TPG 方法. 图1(d) 中, ATPGM 迭代法的残差下降速度略快于 TPG 方法.
图1
图1
$\delta=0.001$
例 3.2 $\textbf{二维椭圆方程参数识别问题}$
考虑在区间为 $\Omega=[0,1]\times [0,1]$
(3.3) $c^{\dagger}(\zeta,\xi)=\sin(3\pi(\zeta-\frac{2}{3}))\sin(3\pi(\xi-\frac{2}{3}))\cdot \mathcal{X}(\zeta)_{[\frac{1}{3},\frac{2}{3}]}\mathcal{X}(\xi)_{[\frac{1}{3},\frac{2}{3}]}$
其中 $\mathcal{X}_A(\zeta)= \begin{cases} 1,\zeta\in A\\ 0,\zeta\notin A \end{cases}$ $A$
假设 $u(c^{\dagger})=c^{\dagger}(\zeta,\xi)(\zeta+\xi)$ $u$ $u^{\delta}$ $\|u^{\delta}-u\|=\delta$ . 使用 $u^{\delta}$ $c$ . 此时, 问题 (1.1) 中所求参数为函数 $c(\zeta,\xi)$ $x_k^{\delta}=c_k^{\delta}$ . 对三种迭代法均设定初始值 $c_0=0$ $\tau=3$ $\eta=0.01,\omega=10, \mu_1=20000$ . 对于 ATPGM 迭代法,动量初始值 $s_0=0$ . 实验中,使用二阶有限差分法将正演问题 (3.2) 离散, 将区间分为 $64\times64$ $LU$ $\delta=0$ $\|u^{\delta}-F(c_k^{\delta})\|\le 0.001$ $\delta\neq0$
与一维实验相同, 自适应调整 $\beta_k^{\delta}$ $\bar{\beta}=0.5$ $\beta_k^{\delta}=0$ $\delta$ $\delta$ 表2 所示.
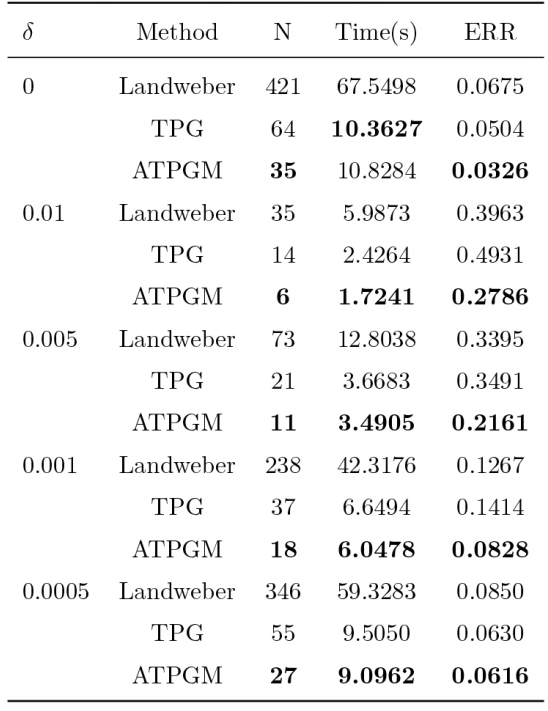
由表2 可看出,在相同噪音水平和停机准则下, ATPGM 迭代法所需迭代步最少, 动量加速技巧可以有效加快 Landweber 迭代正则化方法和 TPG 方法的收敛速度. 随着迭代步的增加,动量项不断累积, 计算机存储与更新动量项,动量系数需要花费额外的时间,在此条件下, ATPGM 迭代法所花时间与 TPG 方法所花时间近似,那么可以看出 ATPGM 迭代法在迭代步和运行时间上都具有明显的优势. 此外, 随着噪音水平 $\delta$
图2 所示为噪声水平 $\delta=0.0005$ 图2 可知, 三种方法均能高精度重构该实验模型,受噪音的干扰, 三个模拟结果图均有局部尖峰.其中, TPG 方法的模拟结果中局部尖峰数量最少且重构结果趋于平滑, 在速度和精度间取得平衡; Landweber 迭代正则化方法的模拟结果中局部尖峰数量较少; ATPGM 迭代法的模拟结果图中局部尖峰数量较多, 在精度上有欠缺, 可能是由于动量项会累积高频误差从而形成了较多的局部尖峰. 图2(e) 再次表明动量加速技巧能够有效加快 Landweber 迭代正则化方法和 TPG 方法的收敛速度. 图2(f) 展示 ATPGM 迭代法的相对误差下降速度最快, 表明 ATPGM 迭代法能够更快速地收敛到真实解, 其牺牲了一定的重构精度以换取速度和效率, 适合对计算时间敏感但容许一定噪声的场景.
图2
图2
$\delta=0.0005$
4 结论
针对 Landweber 迭代正则化方法求解非线性不适定反问题时收敛速度慢的问题, 本文基于两点梯度法, 自适应重球法及动量法, 提出了自适应动量加速两点梯度法(ATPGM). 理论上证明了 ATPGM 迭代法的收敛性, 并基于一维和二维椭圆参数识别问题, 从数值角度验证了 ATPGM 迭代法的快速收敛性. 数值实验结果表明, 相较于 Landweber 迭代正则化方法和两点梯度法, ATPGM 迭代法在迭代次数和运算时间方面具有明显的优势. 此外, 数值结果还表明, ATPGM 迭代法可以作为求解非线性不适定反问题的一种高效的迭代正则化方法.
参考文献
View Option
[1]
谷苒 . 基于启发式停止准则的 Landweber 型迭代及其应用 . 金华 : 浙江师范大学 , 2024
[本文引用: 1]
Gu R Landweber-Type Iterations with Heuristic Stopping Criteria and Their Applications . Jinhua : Zhejiang Normal University , 2024
[本文引用: 1]
[2]
高银霞 . 几类偏微分方程初值识别和源项反演的正则化方法和算法研究 . 兰州 : 兰州理工大学 , 2024
[本文引用: 2]
Gao Y X Regularization Methods and Algorithm Research for Initial Value Identification and Source Term Inversion of Several Types of Partial Differential Equations . Lanzhou : Lanzhou University of Technology , 2024
[本文引用: 2]
[3]
Engl H W Hanke M Neubauer A Regularization of Inverse Problems . Boston : Kluwer Academic Publishers , 1996
[本文引用: 3]
[4]
Schuster T Kaltenbacher B Hofmann B et al . Regularization Methods in Banach Spaces . Berlin : Walter de Gruyter , 2012
[5]
Kaltenbacher B Neubauer A Scherzer O Iterative Regularization Methods for Nonlinear Ill-Posed Problems . Berlin : Walter de Gruyter , 2008
[本文引用: 1]
[6]
王美吉 , 潘状元 . 解非线性不适定问题的一种正则化方法
西安工程大学学报 , 2013 , 27 2 ): 248 -252
[本文引用: 2]
Wang M J Pan Z Y A Regularization method for solving nonlinear ill-posed problems
Journal of Xi'an Polytechnic University , 2013 , 27 2 ): 248 -252
[本文引用: 2]
[7]
Hanke M Neubauer A Scherzer O A convergence analysis of the Landweber iteration for nonlinear ill-posed problems
Numerische Mathematik , 1995 , 72 1 ): 21 -37
DOI:10.1007/s002110050158
URL
[本文引用: 2]
[8]
Landweber L An iteration formula for Fredholm integral equations of the first kind
American Journal of Mathematics , 1951 , 73 3 ): 615 -624
DOI:10.2307/2372313
URL
[本文引用: 2]
[9]
Gao G Han B Tong S A fast two-point gradient algorithm based on sequential subspace optimization method for nonlinear ill-posed problems
Mathematics and Computers in Simulation , 2022 , 192 221 -245
DOI:10.1016/j.matcom.2021.09.004
URL
[本文引用: 1]
[10]
Cao L Han B Convergence analysis of the homotopy perturbation method for solving nonlinear ill-posed operator equations
Computers Mathematics with Applications , 2011 , 61 8 ): 2058 -2061
DOI:10.1016/j.camwa.2010.08.069
URL
[本文引用: 1]
[11]
Long H Han B Tong S A new Kaczmarz-type method and its acceleration for nonlinear ill-posed problems
Inverse Problems , 2019 , 35 5 ): Art 055004
[本文引用: 2]
[12]
Tong S Han B Long H et al . An accelerated sequential subspace optimization method based on homotopy perturbation iteration for nonlinear ill-posed problems
Inverse Problems , 2019 , 35 12 ): Art 125005
[本文引用: 3]
[13]
Gu R Han B Chen Y Fast subspace optimization method for nonlinear inverse problems in Banach spaces with uniformly convex penalty terms
Inverse Problems , 2019 , 35 12 ): Art 125011
[本文引用: 1]
[14]
Burger M Kaltenbacher B Regularizing Newton-Kaczmarz methods for nonlinear ill-posed problems
SIAM Journal on Numerical Analysis , 2006 , 44 1 ): 153 -182
DOI:10.1137/040613779
URL
[本文引用: 2]
[15]
Clason C Jin B A semismooth Newton method for nonlinear parameter identification problems with impulsive noise
SIAM Journal on Imaging Sciences , 2012 , 5 2 ): 505 -536
DOI:10.1137/110826187
URL
[本文引用: 1]
[16]
Hubmer S Ramlau R Convergence analysis of a two-point gradient method for nonlinear ill-posed problems
Inverse Problems , 2017 , 33 9 ): Art 095004
[本文引用: 8]
[17]
Gao G Han B Fu Z et al . A fast data-driven iteratively regularized method with convex penalty for solving ill-posed problems
SIAM Journal on Imaging Sciences , 2023 , 16 2 ): 640 -670
DOI:10.1137/22M1506778
URL
[本文引用: 2]
[18]
邹江艳 , 何清龙 . 基于自适应 BB 步长的修正 Landweber 迭代算法及收敛性分析
运筹学与模糊数学 , 2022 , 12
[本文引用: 1]
Zou J Y He Q L Modified landweber iterative algorithm with adaptive barzilai-borwein step-size and convergence analysis
Operations Research and Fuzziology , 2022 , 12
[本文引用: 1]
[19]
Nesterov Y A method for solving the convex programming problem with convergence rate O (1/$k^2$ )
Dokl Akad Nauk Sssr . 1983 , 269
[本文引用: 2]
[20]
Attouch H Peypouquet J The rate of convergence of Nesterov's accelerated forward-backward method is actually faster than $1/k^2$
SIAM Journal on Optimization , 2016 , 26 3 ): 1824 -1834
DOI:10.1137/15M1046095
URL
[本文引用: 2]
[21]
Dozat T Incorporating Nesterov Momentum Into Adam . Chongqing : Computer Science , 2016
[本文引用: 1]
[22]
张艳 , 何清龙 . 基于动量法的修正 Landweber 迭代算法
重庆工商大学学报 (自然科学版) , https://link.cnki.net/urlid/50.1155.n.20241113.0932.004, [2025-10-22]
URL
[本文引用: 6]
Zhang Y He Q L Modified Landweber iterative algorithm based on momentum method
Journal of Chongqing Technology and Business University (Natural Science Edition) , https://link.cnki.net/urlid/50.1155.n.20241113.0932.004, [2025-10-22]
URL
[本文引用: 6]
[23]
Sutskever I Martens J Dahl G et al . On the importance of initialization and momentum in deep learning//International conference on machine learning
PMLR , 2013 , 28 1139 -1147
[本文引用: 1]
[24]
Kingma D P Adam: A method for stochastic optimization . arXiv preprint arXiv: 1412.6980, 2014
[本文引用: 1]
[25]
Polyak B T Some methods of speeding up the convergence of iteration methods
Ussr Computational Mathematics and Mathematical Physics , 1964 , 4 5 ): 1 -17
[本文引用: 1]
[27]
Jin Q Huang Q An adaptive heavy ball method for ill-posed inverse problems
SIAM Journal on Imaging Sciences , 2024 , 17 4 ): 2212 -2241
DOI:10.1137/24M1651721
URL
[本文引用: 2]
[28]
Jin Q Adaptive Nesterov momentum method for solving ill-posed inverse problems
Inverse Problems , 2025 , 41 2 ): Art 025005
[本文引用: 1]
1
2024
... 在科学计算和工程应用中, 反问题广泛存在, 其已经发展成为横跨数学, 物理, 医疗, 信号勘察等众多科学的一个热门研究领域[1 ] . 随着科技水平的提高, 实际生活的需要促使理论研究成果与丰硕的科技创新并驾齐驱, 数学物理反问题引起了众多研究者的广泛关注与深入探究[2 ] . 由于绝大多数反问题都是不适定问题, 为了得到稳定近似解必须采取正则化策略进行求解, 如变分正则化方法和迭代正则化方法[2 5 ] . ...
1
2024
... 在科学计算和工程应用中, 反问题广泛存在, 其已经发展成为横跨数学, 物理, 医疗, 信号勘察等众多科学的一个热门研究领域[1 ] . 随着科技水平的提高, 实际生活的需要促使理论研究成果与丰硕的科技创新并驾齐驱, 数学物理反问题引起了众多研究者的广泛关注与深入探究[2 ] . 由于绝大多数反问题都是不适定问题, 为了得到稳定近似解必须采取正则化策略进行求解, 如变分正则化方法和迭代正则化方法[2 5 ] . ...
2
2024
... 在科学计算和工程应用中, 反问题广泛存在, 其已经发展成为横跨数学, 物理, 医疗, 信号勘察等众多科学的一个热门研究领域[1 ] . 随着科技水平的提高, 实际生活的需要促使理论研究成果与丰硕的科技创新并驾齐驱, 数学物理反问题引起了众多研究者的广泛关注与深入探究[2 ] . 由于绝大多数反问题都是不适定问题, 为了得到稳定近似解必须采取正则化策略进行求解, 如变分正则化方法和迭代正则化方法[2 5 ] . ...
... [2 5 ]. ...
2
2024
... 在科学计算和工程应用中, 反问题广泛存在, 其已经发展成为横跨数学, 物理, 医疗, 信号勘察等众多科学的一个热门研究领域[1 ] . 随着科技水平的提高, 实际生活的需要促使理论研究成果与丰硕的科技创新并驾齐驱, 数学物理反问题引起了众多研究者的广泛关注与深入探究[2 ] . 由于绝大多数反问题都是不适定问题, 为了得到稳定近似解必须采取正则化策略进行求解, 如变分正则化方法和迭代正则化方法[2 5 ] . ...
... [2 5 ]. ...
3
1996
... 求解问题 (1.1) 的常用方法为 Landweber 迭代正则化方法[3 ,7 ,8 ] , 其迭代格式为 ...
... Landweber 迭代正则化方法的收敛性在文献 [3 ,7 ,8 ] 中有详细说明. 本文实验中, 三种方法选取统一的修正步长 ...
... 从文献 [3 ] 可知, $F$ $F$ $\acute{\rm e}$ $h,\sigma\in L^ 2(\Omega)$
1
2008
... 在科学计算和工程应用中, 反问题广泛存在, 其已经发展成为横跨数学, 物理, 医疗, 信号勘察等众多科学的一个热门研究领域[1 ] . 随着科技水平的提高, 实际生活的需要促使理论研究成果与丰硕的科技创新并驾齐驱, 数学物理反问题引起了众多研究者的广泛关注与深入探究[2 ] . 由于绝大多数反问题都是不适定问题, 为了得到稳定近似解必须采取正则化策略进行求解, 如变分正则化方法和迭代正则化方法[2 5 ] . ...
解非线性不适定问题的一种正则化方法
2
2013
... 其中 $F:\mathcal{D}(F)\subset \mathcal{X}\rightarrow \mathcal{Y}$ $\mathcal{X}$ $\mathcal{Y}$ $y$ . 在本文中, 假设问题 (1.1) 的解总是存在且算子 $F$ $\acute{\rm e}$ $y^{\delta}$ [6 ] ...
... 为了分析简化, 引入符号: $r_k^{\delta}:=F(z_k^{\delta})-y^{\delta}, g_k^{\delta}:=F^{\prime}(z_k^{\delta})^*r_k^{\delta}$ . 由假设 2.1 和假设 2.2, 可以证明如下命题[6 ] . ...
A Regularization method for solving nonlinear ill-posed problems
2
2013
... 其中 $F:\mathcal{D}(F)\subset \mathcal{X}\rightarrow \mathcal{Y}$ $\mathcal{X}$ $\mathcal{Y}$ $y$ . 在本文中, 假设问题 (1.1) 的解总是存在且算子 $F$ $\acute{\rm e}$ $y^{\delta}$ [6 ] ...
... 为了分析简化, 引入符号: $r_k^{\delta}:=F(z_k^{\delta})-y^{\delta}, g_k^{\delta}:=F^{\prime}(z_k^{\delta})^*r_k^{\delta}$ . 由假设 2.1 和假设 2.2, 可以证明如下命题[6 ] . ...
A convergence analysis of the Landweber iteration for nonlinear ill-posed problems
2
1995
... 求解问题 (1.1) 的常用方法为 Landweber 迭代正则化方法[3 ,7 ,8 ] , 其迭代格式为 ...
... Landweber 迭代正则化方法的收敛性在文献 [3 ,7 ,8 ] 中有详细说明. 本文实验中, 三种方法选取统一的修正步长 ...
An iteration formula for Fredholm integral equations of the first kind
2
1951
... 求解问题 (1.1) 的常用方法为 Landweber 迭代正则化方法[3 ,7 ,8 ] , 其迭代格式为 ...
... Landweber 迭代正则化方法的收敛性在文献 [3 ,7 ,8 ] 中有详细说明. 本文实验中, 三种方法选取统一的修正步长 ...
A fast two-point gradient algorithm based on sequential subspace optimization method for nonlinear ill-posed problems
1
2022
... 其中 $k$ $x_0^{\delta}=x_0$ $F^{\prime}$ $F$ $\acute{\rm e}$ $*$ $F$ $\alpha_k^{\delta}$ $\alpha_k^{\delta}$ [9 ] . 在数据存在噪声的情况下, 本文采用偏差原理作为停机准则, 即 ...
Convergence analysis of the homotopy perturbation method for solving nonlinear ill-posed operator equations
1
2011
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
A new Kaczmarz-type method and its acceleration for nonlinear ill-posed problems
2
2019
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
... [11 ,12 ,16 ]等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
An accelerated sequential subspace optimization method based on homotopy perturbation iteration for nonlinear ill-posed problems
3
2019
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
... [12 ,13 ], Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
... ,12 ,16 ]等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
Fast subspace optimization method for nonlinear inverse problems in Banach spaces with uniformly convex penalty terms
1
2019
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
Regularizing Newton-Kaczmarz methods for nonlinear ill-posed problems
2
2006
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
... [14 ,15 ]和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
A semismooth Newton method for nonlinear parameter identification problems with impulsive noise
1
2012
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
Convergence analysis of a two-point gradient method for nonlinear ill-posed problems
8
2017
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
... Nesterov 加速方案最初被引入用于求解凸规划问题, 该方案在实现上效果显著, 并大幅提升了收敛速度, 其数学框架为动量法奠定了一定的理论基础[17 ,19 ,20 ] . 此外, Hubmer和 Ramlau 在 Nesterov 加速技巧[19 ,20 ] 的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为 ...
... 其中初始值 $x_0^{\delta}=x_{-1}^{\delta}=x_0$ $ \lambda_k^{\delta}>0$ 16 ]). TPG 方法通过引入前一步的迭代信息进行外推加速, 实现了对 Landweber 迭代正则化方法的加速, 但需额外计算组合参数 $\lambda_k^{\delta}$
... 这对所有 $0\le l<k_*$ $k_*$ $\mu$ [16 ] , 利用归纳假设法推导 $\Delta_{l+1}\le 0$ . ...
... 命题 2.3 设 $x_*$ $F(x)=y$ $x_k$ $\delta=0$ . 假设当 $k\rightarrow \infty$ $\|x_k-x_*\|\rightarrow \varepsilon, \varepsilon\ge 0$ $k\rightarrow \infty$ $\lambda_k^0\|x_k-x_{k-1}\|\rightarrow 0$ $\|s_{k+1}\|\rightarrow 0$ [16 ] ...
... 证 使用 (1.7) 式的定义以及夹逼原则容易证明该结论. 可参考文献 [16 ]. ...
... 这意味着当 $k\rightarrow\infty$ $\lambda_k^0\rightarrow 0$ $\delta = 0$ 16 ,定理 2.8] 和文献 [27 ,定理 3.5] 证明类似, 可以证明定理 2.1 中精确数据的收敛性. ...
... 根据定理 2.1 的结论, 可以进一步推导出在相同的假设条件下, 迭代序列 $\{x_k\}$ $x_*$ $\{x_k\}$ $\{z_k\}$ $\delta=0$ $\delta\neq 0$ [16 ,22 ] . ...
A fast data-driven iteratively regularized method with convex penalty for solving ill-posed problems
2
2023
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
... Nesterov 加速方案最初被引入用于求解凸规划问题, 该方案在实现上效果显著, 并大幅提升了收敛速度, 其数学框架为动量法奠定了一定的理论基础[17 ,19 ,20 ] . 此外, Hubmer和 Ramlau 在 Nesterov 加速技巧[19 ,20 ] 的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为 ...
基于自适应 BB 步长的修正 Landweber 迭代算法及收敛性分析
1
2022
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
Modified landweber iterative algorithm with adaptive barzilai-borwein step-size and convergence analysis
1
2022
... Landweber 迭代正则化方法是一种求解线性与非线性反问题的经典方法, 因其良好的稳定性且每次迭代计算复杂度低而被广泛应用. 众所周知, Landweber 迭代法收敛速度往往较慢, 极大限制其在现实问题中的广泛应用. 学术界针对其收敛速度慢的问题提出了多种加速方法, 如同伦摄动法[10 12 ] , 序列子空间优化法[12 ,13 ] , Kaczmarz 型方法[11 ,14 ] , 牛顿型方法[14 ,15 ] 和两点梯度法[11 ,12 ,16 ] 等, 在一定程度上提高了 Landweber 迭代正则化方法的适用性[17 ] . 因此, 对 Landweber 迭代正则化方法的加速研究具有重要的理论意义和实际应用价值[18 ] ...
A method for solving the convex programming problem with convergence rate O (1/$k^2$ )
2
1983
... Nesterov 加速方案最初被引入用于求解凸规划问题, 该方案在实现上效果显著, 并大幅提升了收敛速度, 其数学框架为动量法奠定了一定的理论基础[17 ,19 ,20 ] . 此外, Hubmer和 Ramlau 在 Nesterov 加速技巧[19 ,20 ] 的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为 ...
... [19 ,20 ]的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为 ...
The rate of convergence of Nesterov's accelerated forward-backward method is actually faster than $1/k^2$
2
2016
... Nesterov 加速方案最初被引入用于求解凸规划问题, 该方案在实现上效果显著, 并大幅提升了收敛速度, 其数学框架为动量法奠定了一定的理论基础[17 ,19 ,20 ] . 此外, Hubmer和 Ramlau 在 Nesterov 加速技巧[19 ,20 ] 的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为 ...
... ,20 ]的基础上提出两点梯度法 (TPG)[16 ] , 并给出相应的收敛性分析. 该方法的迭代更新格式为 ...
1
2016
... 动量法最初被用于加速梯度下降法, 在迭代算法中加入动量项, 可使得算法在迭代过程中跳出局部最优点, 快速向全局最优点靠近, 提高收敛速度[21 ,22 ] . 该方法的主要思想是利用累积动量近似当前迭代步的下降方向, 每次迭代的梯度可看作加速度[22 ] . 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
基于动量法的修正 Landweber 迭代算法
6
... 动量法最初被用于加速梯度下降法, 在迭代算法中加入动量项, 可使得算法在迭代过程中跳出局部最优点, 快速向全局最优点靠近, 提高收敛速度[21 ,22 ] . 该方法的主要思想是利用累积动量近似当前迭代步的下降方向, 每次迭代的梯度可看作加速度[22 ] . 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
... [22 ]. 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
... [22 ]将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
... 根据定理 2.1 的结论, 可以进一步推导出在相同的假设条件下, 迭代序列 $\{x_k\}$ $x_*$ $\{x_k\}$ $\{z_k\}$ $\delta=0$ $\delta\neq 0$ [16 ,22 ] . ...
... 在本节中, 采用文献 [22 ] 中的数值实验例子, 即一维和二维的椭圆方程参数识别反问题进行数值模拟展示所提出的 ATPGM 迭代法, 相较于 Landweber 迭代正则化方法和 TPG 方法的加速效果. 首先给出这些方法的简要描述. ...
... 注意, 为了保证 ATPGM 迭代法数据残差 $\|y^{\delta}-F(z_k^{\delta})\|$ [22 ] . ...
Modified Landweber iterative algorithm based on momentum method
6
... 动量法最初被用于加速梯度下降法, 在迭代算法中加入动量项, 可使得算法在迭代过程中跳出局部最优点, 快速向全局最优点靠近, 提高收敛速度[21 ,22 ] . 该方法的主要思想是利用累积动量近似当前迭代步的下降方向, 每次迭代的梯度可看作加速度[22 ] . 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
... [22 ]. 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
... [22 ]将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
... 根据定理 2.1 的结论, 可以进一步推导出在相同的假设条件下, 迭代序列 $\{x_k\}$ $x_*$ $\{x_k\}$ $\{z_k\}$ $\delta=0$ $\delta\neq 0$ [16 ,22 ] . ...
... 在本节中, 采用文献 [22 ] 中的数值实验例子, 即一维和二维的椭圆方程参数识别反问题进行数值模拟展示所提出的 ATPGM 迭代法, 相较于 Landweber 迭代正则化方法和 TPG 方法的加速效果. 首先给出这些方法的简要描述. ...
... 注意, 为了保证 ATPGM 迭代法数据残差 $\|y^{\delta}-F(z_k^{\delta})\|$ [22 ] . ...
On the importance of initialization and momentum in deep learning//International conference on machine learning
1
2013
... 动量法最初被用于加速梯度下降法, 在迭代算法中加入动量项, 可使得算法在迭代过程中跳出局部最优点, 快速向全局最优点靠近, 提高收敛速度[21 ,22 ] . 该方法的主要思想是利用累积动量近似当前迭代步的下降方向, 每次迭代的梯度可看作加速度[22 ] . 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
1
2014
... 动量法最初被用于加速梯度下降法, 在迭代算法中加入动量项, 可使得算法在迭代过程中跳出局部最优点, 快速向全局最优点靠近, 提高收敛速度[21 ,22 ] . 该方法的主要思想是利用累积动量近似当前迭代步的下降方向, 每次迭代的梯度可看作加速度[22 ] . 张艳等[22 ] 将动量法与 Landweber 迭代正则化方法结合, 充分利用历史梯度信息对 Landweber 迭代正则化方法进行加速, 通过数值实验验证了其有效性. Sutskever 等[23 ] 将动量法运用到深度学习中验证了其有效性并广泛推广了动量法的应用. Kingma[24 ] 将动量法与自适应学习率结合提出了 Adam 算法, 该算法兼顾了动量的加速效果与自适应学习率的稳定性, 成为了使用最广泛的优化方法之一. ...
Some methods of speeding up the convergence of iteration methods
1
1964
... 重球法 (HB) 通过添加动量项扩展了梯度下降法, 该动量项整合了当前迭代信息与前一步迭代信息之间的差异, 从而引导下一步迭代向解方向移动[25 ,26 ] . HB 算法不仅需要调整其动量参数, 还需优化步长, 这使得算法运行更加复杂[26 ] . 2024 年, Jin 等[27 ] 提出了自适应重球法, 其迭代格式为 ...
An adaptive polyak heavy-ball method
2
2022
... 重球法 (HB) 通过添加动量项扩展了梯度下降法, 该动量项整合了当前迭代信息与前一步迭代信息之间的差异, 从而引导下一步迭代向解方向移动[25 ,26 ] . HB 算法不仅需要调整其动量参数, 还需优化步长, 这使得算法运行更加复杂[26 ] . 2024 年, Jin 等[27 ] 提出了自适应重球法, 其迭代格式为 ...
... [26 ]. 2024 年, Jin 等[27 ] 提出了自适应重球法, 其迭代格式为 ...
An adaptive heavy ball method for ill-posed inverse problems
2
2024
... 重球法 (HB) 通过添加动量项扩展了梯度下降法, 该动量项整合了当前迭代信息与前一步迭代信息之间的差异, 从而引导下一步迭代向解方向移动[25 ,26 ] . HB 算法不仅需要调整其动量参数, 还需优化步长, 这使得算法运行更加复杂[26 ] . 2024 年, Jin 等[27 ] 提出了自适应重球法, 其迭代格式为 ...
... 这意味着当 $k\rightarrow\infty$ $\lambda_k^0\rightarrow 0$ $\delta = 0$ 16 ,定理 2.8] 和文献 [27 ,定理 3.5] 证明类似, 可以证明定理 2.1 中精确数据的收敛性. ...
Adaptive Nesterov momentum method for solving ill-posed inverse problems
1
2025
... 采用关于 $z_k^{\delta}$ $x_k^{\delta}$ [28 ] . 记满足不等式 (2.14) 的最小整数为 $k_*=k_*(\delta,y^{\delta})$ . ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}